Data Integrity in the GxP Chromatography Laboratory, Part I: Sampling and Sample Preparation
LCGC North America
Part I of this series on practical perspectives of data integrity focuses on sample management, transport, and preparation.
Data integrity is the hottest topic in the pharmaceutical industry today and many of the issues involved are focused on the chromatography laboratory. Chromatographic analysis can be subverted to manipulate failing results into passing ones and therefore needs to be controlled to ensure the integrity of the results. This article is the first part of a six-part series looking at data integrity from a practical perspective within a regulated good laboratory practice (GLP) or good manufacturing practice (GMP) chromatography laboratory. The principles described here are also applicable to laboratories wanting to ensure quality work. Part I focuses on sample management, transport, and preparation.
This is the first of a six-part series of articles looking at data integrity from a practical perspective within a regulated good laboratory practice (GLP) or good manufacturing practice (GMP) chromatography laboratory. The principles described here are also applicable to laboratories wanting to ensure quality work, such as requirements in International Organization for Standardization (ISO) 17025.
Here, we focus on sample management, transport, and preparation.
Visualizing the Scope of Data Integrity
To understand the scope of data integrity, a four-layer model has been developed. The full GMP model is shown in Figure 1 (1) and the analytical portion was discussed in Spectroscopy (2). The four layers are
- Foundation: right corporate culture and ethos for data integrity
- Level 1: right instrument or system for the job
- Level 2: right analytical procedure for the job
- Level 3: right analysis for the right reportable result


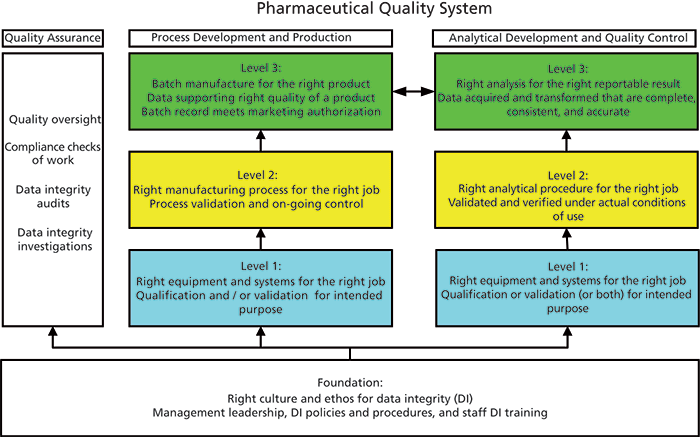
Figure 1: A four-layer data integrity model.
In the first five parts of this series we will focus on Level 3, and part VI will look at the foundation layer. Notwithstanding, remember that for the work at Level 3 to ensure data integrity the other three layers must be in place and functioning. We assume that instruments are qualified and computerized systems and analytical procedures are validated. In addition, readers are aware of the ALCOA (attributable, legible, contemporaneous, original and accurate) principles of documentation that can be found in the appendix of the World Health Organization (WHO) data integrity guidance (3).
The Chromatographic Process
The first five parts of this series will look specifically at the chromatographic analysis as shown in Figure 2 (4). Here we can see the full scope of an analysis involving chromatography from sampling to generation of the reportable result. At the top of the figure there are seven stages of an analysis with the key items required for ensuring data integrity. There are also
- chromatography data systems with audit trail entries for review,
- scope of the second-person review, and
- what constitutes either complete data and raw data for an analysis.

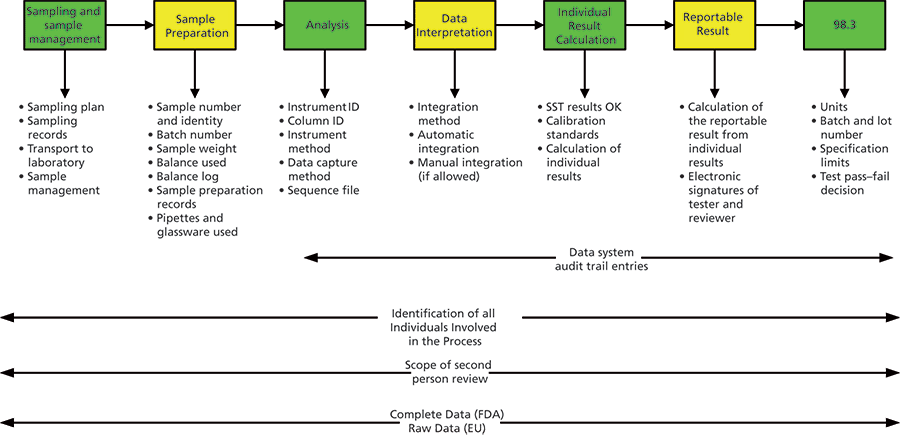
Figure 2: The chromatographic process from sampling to reportable result.
Data Integrity Articles
The scope of this series of six articles is shown in Figure 3 and explained in more detail below:
1. Sampling and sample preparation: Two of the most critical areas in analysis that are mostly manual and could be easily manipulated.
2. Setting up a chromatograph and acquiring data: What should be done to ensure the correct set up of an instrument, how to run system suitability test samples, and the acquisition of data.
3. Integrating and interpreting data: What should be done to control integration and interpretation of the chromatographic runs.
4. Reporting the results: Calculation of the reportable result from an analysis and handling out of specification results and data that have been invalidated in the testing process.
5. Second-person review: Reviewing the records to see that work has been carried out correctly, to ensure that the complete record of testing is present, and to determine if any work is incorrect or potentially falsified.
6. Culture, training, and metrics: Changing behavior in an organization, training for data integrity, and monitoring analytical work in the laboratory.

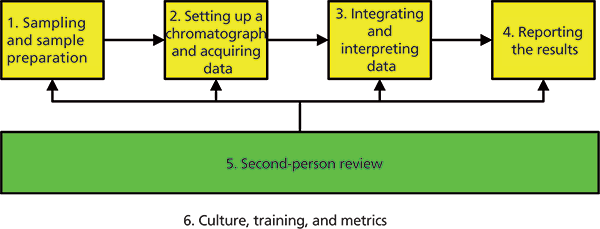
Figure 3: Scope of the articles for data integrity in the GxP chromatography laboratory.
Data Integrity Issues with Sampling and Sample Preparation
The first two stages of the analytical process (Figure 2), sampling and sample preparation, have all the right prerequisites for data integrity issues. Consider the following issues that can be found in most laboratory sampling and sample preparation processes:
- actions are executed by people (sometimes interacting with instruments or systems);
- text, numbers, and labels are involved;
- many steps of the operation are not second-person reviewed at the time of data entry or labeling; and
- errors can lead to incorrect business decisions.
Sampling and sample preparation represents a hidden problem: It is not covered in any data integrity guidance from a regulatory agency. However, if sampling and sample preparation are not controlled, business decisions can be made on inaccurate information.
As we step through this data integrity minefield, consider all the possible answers to the question: What could possibly go wrong?
Current Practice: Sample Collection
Proper sample collection and identification is critical for test result values that accurately characterize the process being tested. Incorrect sample identity can happen in many ways:
- batch printing identification labels from laboratory information management system (LIMS), electronic laboratory notebook (ELN), or lab execution systems offers the opportunity to select the wrong label from the sheet and affix it to the sample;
- incorrectly transcribing the sampling location to the sample container while reading the location from a paper list (or report); and
- wrapping paper labels around samples that are shuffled during transport and incorrectly reapplied to samples.
After sample identity is compromised, data integrity is also lost, and it becomes impossible to reconstruct data with confidence.
In addition to the above errors, consider who will manage them: It is not your senior analyst, who understands the importance of the right sample location and the right container or transport system to preserve sample integrity. Instead, these errors are managed by the contract person who has a few months on the job, with a minimal amount of training to collect and deliver samples. Faced with the fact that eight sample labels, attached with rubber bands, are now shuffled inside a box, he or she will attempt to correctly affix the labels, rather than report it and risk disciplinary action. As a result of this hidden knowledge, the lab might have a set of atypical results with no assignable cause known for them.
Once sample identity is compromised, a new sample can sometimes be collected, while specific point-in-time samples will simply be lost, as the process has moved past that process point.
So, how can we overcome these potential data integrity issues?
Good Practice: Sample Collection
From a data integrity perspective, a sampling process should be designed to minimize incorrect data entries and to ensure sample identity at all times until sample disposal. It should not permit recording of original data (raw data) on the sample or label, and should prevent the loss of sample information (including identity) from handling and transport.
Best-in-class sample collection processes collect sample data in an electronic system, which allows users to access the system to view sample information, typically with mobile devices. Another advantage is that sample labels include barcoded (or radio-frequency identification [RFID]) number or character strings that can be affixed to containers at any time, because they have no meaning until associated with a specific sample.
This approach allows for a wide range of possible label materials and sampling data to be collected immediately in electronic form using noncontact readers in a mobile computer system. Attribution of action is supplied by the user identity of the person logged into the system account, rather than manual entries. When sampling locations (or other routine sample information) are also barcoded for rapid entry, human data entry is minimized, and the process requires less time. A true win-win situation.
Sample Transport
Some samples require timely transport under specific conditions (for example, temperature or humidity) to ensure accuracy of test results. For such samples, it is imperative to ensure compliant transport to the test facility. Transport can be a weak link in the process, especially when third-parties are involved in transport. Situations where a single temperature or humidity is required for all samples may represent a low risk, but when multiple humidity and temperatures are required for delivery of samples, risks rapidly rise. Remember, the integrity of test results is tied to the correct storage and transport of these samples, which could be in the hands of a person with little training and little understanding of the importance of proper storage and timely transport.
In cases where transport conditions are critical, automated temperature recording with remote data collection is a preferred solution. At a minimum, calibrated portable data loggers should be transported with the samples to collect data, providing evidence that the samples remained within a controlled environment before receipt. In addition, an investment in transportable data loggers enables the ability to review the real sample conditions afterward. Transport data may hold the key to understanding an unusual laboratory test result from what seemed to be a process in control. Additionally, data logger results can be reviewed and analyzed (such as kinetic mean temperature) to verify the adequacy of the sample, transport, and receipt process. In situations where data loggers are not feasible, sample stability studies can provide evidence that temperature excursions will not significantly impact the reportable test results for specific sample, temperature, or time ranges.
Upon arrival at the testing facility, critical samples should be removed from the transport containers by a laboratory analyst to verify that correct transport containers and conditions were used while delivering the samples. If the delivery person is permitted to remove samples from transport containers and place them in a receipt storage area, information about sample transport conditions is lost.
Sample Receipt
Sample receipt begins when delivery is made to the testing facility. The best scenario is when a trained person immediately receives the samples, records them in the laboratory data system or logbook, and places them in correct storage until testing begins. Reality can be far from ideal: Busy labs may permit samples to sit for as many as several hours before processing and storing them.
Once again, manual data entry provides opportunity for errors in sample locations, sample identity, or sampling comments. In addition, there might be original data attached to the samples (such as paper records) that must be either retained, moved into electronic format, or scanned and retained as an image (true copy). It is important to ensure that all paper records, including information on sample labels, is retained.
The best-in-class receipt process is one that does not require the receiving analyst to make any entry from the keyboard: rather, samples are identified with scanned barcode labels or RFID tags, and comments about the sample are entered directly into the laboratory system by the person who observes them. Unfortunately, this robust approach to data is difficult when external parties are involved in sample collection, transport, or receipt.
Current Practice: Sample Preparation
Sample preparation provides many opportunities to compromise the integrity of test results. Acknowledging that every human interaction is a data integrity risk point, and sample preparation for most methods is a series of manual operations, a "perfect storm" for data integrity lapses is created. Analysts can make small changes in execution that can bias results in a desired direction (toward product acceptance), such as
- adding a little extra analyte,
- slightly under or over-filling a volumetric flask of the reference standard, and
- recording a slightly different weight for the sample or reference standard.
These are but a few possible risks when preparing samples or standards for assay. These are risks to data integrity over and above those already present because of human errors in weighing, transfer, and manual data recording.
Fortunately, some sample preparation actions can be later verified: For instance, an analyst can view the volumetric flask to verify that 1 mL was removed for a dilution or instrument injection. Weights can be printed to a report and retained for later verification. On the other hand, a weighed powder, dissolved in a liquid, cannot be verified with any certainty unless the operation is observed contemporaneously.
To be trustworthy, manual sample preparation needs a second set of eyes viewing it as it is performed, but this approach is normally seen as economically unfeasible. Therefore, we are then forced to either rely on the quality culture (and lack of incentives or fear) to trust analysts to act responsibly on the behalf of patients, or develop automated (or semiautomated) sample preparation methods that remove the human from the sample preparation process.
The human option-trust your people-has been the only option for laboratories in the past. The automated option was limited and expensive. It was seldom interfaced to other systems for data sharing, and it lacked basic security and integrity capabilities such as individual user accounts. Consequently, beyond high sample volume throughput, there was little else to entice laboratories to move toward automated sample preparation.
The end product is an analyte preparation that is ready to be placed into an autosampler rack or directly injected into the chromatography system. Preserving the identity of the analyte preparation before and after injection is critical. Relying on sample position alone is a risky proposition, because a dropped autosampler can destroy all positions, and errors happen when creating a manual preparation list to correlate sample position with sample identity. As before, the recommended solution is barcoding. Some vendors have begun to offer autosamplers that read barcodes as samples are injected, to ensure the identity of injections sequences. Like sample labels above, preparation containers can have unique number or text sequences that are assigned to a preparation as the container is selected for use. This unique identifier can be recorded (via reader) in the lab records for later review and troubleshooting (if needed). If laboratory records are paper, small labels printed in duplicate can be affixed to the sample preparation container and the other affixed to the paper record. This step creates a means to preserve preparation identity while testing, and for post-assay investigations, if required.
Automate the Sample Preparation Process
The technology option has arrived. Robotics have put automated sample preparation in range for most analytical methods. From a data integrity perspective, it is a win. Automated preparation removes the human from dilutions and extractions, resulting in greater consistency. It provides accurate and trusted timestamps for all actions-which permit troubleshooting, should the need appear, and prevents ergonomic injuries. In addition, automated preparation generates and records data without human interference. In other words, automation now provides better data integrity in addition to ergonomic and productivity benefits.
Taken together, sampling presents a significant part of the testing process where accuracy and integrity can be lost, often without the ability to reconstruct failing steps. It is an area of regulated operations that begs for better practices and the use of technology to reduce risks in delivering a statistically relevant sample to the instrument for analysis.
Is Management the Problem?
In many organizations, management wants data integrity issues to be remediated quickly and at the lowest cost. Sampling and transport is viewed as a cost to be reduced, with a minimum of attention. This bias has resulted in little attention to the risks (and mitigations) involved in sample management and sample preparation. The problem is that unless there is investment in automation, companies will still be left with high risk manual and error prone sampling and sample preparation processes requiring more effort to review the records and exposure to regulatory scrutiny.
Summary
In the first part of this six-part series we looked at the data integrity issues associated with sample collection, transport, and preparation for chromatographic analysis. In general, these processes are manual and paper based and not covered by any data integrity guidance documents. They are data integrity black holes.
So far, we have traveled in our data integrity journey from the sample to the vial ready for injection into the chromatograph. In part II of this series we will look at the data integrity issues associated with setting up the chromatograph and acquiring the data.
References
(1) R.D. McDowall, Ed., Validation of Chromatography Data Systems: Ensuring Data Integrity, Meeting Business and Regulatory Requirements, Second Edition (Royal Society of Chemistry, Cambridge, UK, 2017).
(2) R.D. McDowall, Spectroscopy 31(4), 14–23 (2016).
(3) World Health Organization (WHO), Technical Report Series No.996 Annex 5 Guidance on Good Data and Records Management Practices (WHO, Geneva, Switzerland, 2016).
(4) R.D. McDowall, Data Integrity and Data Governance: Practical Implementation in Regulated Laboratories (Royal Society of Chemistry, Cambridge, UK, 2018).
Mark E. Newton is the Principal at Heartland QA in Lebanon, Indiana.
R.D. McDowall is the Director of RD McDowall Limited in the UK.
Direct correspondence to: rdmcdowall@btconnect.com










Thermodynamic Insights into Organic Solvent Extraction for Chemical Analysis of Medical Devices
April 16th 2025A new study, published by a researcher from Chemical Characterization Solutions in Minnesota, explored a new approach for sample preparation for the chemical characterization of medical devices.



Study Explores Thin-Film Extraction of Biogenic Amines via HPLC-MS/MS
March 27th 2025Scientists from Tabriz University and the University of Tabriz explored cellulose acetate-UiO-66-COOH as an affordable coating sorbent for thin film extraction of biogenic amines from cheese and alcohol-free beverages using HPLC-MS/MS.

Multi-Step Preparative LC–MS Workflow for Peptide Purification
March 21st 2025This article introduces a multi-step preparative purification workflow for synthetic peptides using liquid chromatography–mass spectrometry (LC–MS). The process involves optimizing separation conditions, scaling-up, fractionating, and confirming purity and recovery, using a single LC–MS system. High purity and recovery rates for synthetic peptides such as parathormone (PTH) are achieved. The method allows efficient purification and accurate confirmation of peptide synthesis and is suitable for handling complex preparative purification tasks.


