Common Problems with Method Optimization in Pharmaceutical Analysis
The various steps of an experimental design-based approach are considered and the problems that arise from wrong choices are described.
Experimental design or sequential approaches can be used to optimize separations in pharmaceutical analysis However, the choices made by the analysts setting up the experiments are not always the best and may create problems. In this article the different steps of an experimental design-based approach are considered and the problems that arise from the wrong choices are discussed.
In previous articles we have discussed the experimental designs that can be applied in method development and optimization as well as the analysis of this data (1–4). In recent articles we described a method development approach for drug impurity profiles (5,6). This approach is a variant on the common experimental design one. In an experimental design approach one first determines the most important factors from screening design results. The responses of the method are then modelled as a function of these latter factors and the optimal factor combination determined from the results of response surface designs. For drug impurity profiling we could skip the screening step since we usually know in reversed-phase chromatography which factors have the largest influence on the selectivity. This allows the use of a sequential approach in method optimization, where some steps included small designs (5,6).
However, in some manuscripts originating from both the pharmaceutical industry and the academic world, some steps from the experimental design [or design of experiments (DoE)] approach are not properly applied, leading to problems: either with the applied designs, in the practical execution of the design or in the data handling steps. We will limit ourselves in the rest of this article to the application response surface designs. The different steps in a DoE approach are the selection of the factors and their levels, the selection of the appropriate design to examine the factors, the selection of the response(s) to consider, the execution of the design experiments and the data handling.
The number of factors to optimize should preferably be low (i.e., two or three). These most important factors are, for example, selected based on the results of a screening design performed earlier. Regularly, optimization designs are executed for four to six factors. Such designs require a considerable number of experiments, but determining the best conditions from it is far from obvious and we will discuss this later. Moreover, it is rare that such a high number of factors would significantly affect the method. Therefore it is better to make an a priori selection of the important factors in a preceding screening step. The factors are best defined in such a way that they have a physico-chemical meaning that is easy to understand by the users. For example, pH can be defined as a factor. Everybody knows its meaning and its influence could be derived and interpreted from the design results. Even though pH could also be split in the concentrations of its acidic and basic compounds that might be included as two factors in a design, the physicochemical interpretation of their effects is far less evident.
Factor levels during optimization are selected in an interval that is as broad as possible and that are, for example, limited by the product to be optimized or the limits of the applied technique. For instance, if DoE is applied to optimize a formulation, such as a tablet, then the most extreme levels (as well as their combination) should be tested preliminarily to verify whether these extremes still result in the desired product (i.e., the tablet). In chromatography, the pH, for example, might be limited depending on the type of columns used.
Based on the number of factors to be examined, an experimental design is selected. We discussed the most frequently applied response surface designs in reference 3. It concerns designs with at least three levels for each factor. When examining four or more factors the required number of experiments is high. For example, when applying a central composite design studying 4, 5 or 6 factors requires at least 25, 43 and 77 experiments, respectively. This is another reason to keep the number of factors examined limited. Often a number of replicated experiments, usually of the centre point, are added to the experimental set-up. They are used to estimate the experimental error and are later applied in the data interpretation to indicate non-significant terms in the models built. This will be discussed later.
The responses measured should allow the prediction of the best conditions, such as those where the worst separated peak pair is best separated. At first sight a response indicating the degree or the quality of separation, such as the selectivity factor, α, or the resolution, Rs, seems appropriate for this purpose. To predict the best conditions the response is modelled as a function of the factors examined, usually applying a quadratic model. For instance, for considering two factors:


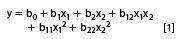
where y is the response; b0 the intercept; and bi the model coefficients. For more than two factors similar models can be built containing more terms (4).
However, modelling resolution or the selectivity factor from the measured design values is usually not recommended, unless no changes in elution sequence occur among all the experiments, which in method optimization is very improbable. When changes in elution sequence occur, there are then two objections against the modelling of the above responses.
First, a situation where two peaks A and B are equally separated but eluting in a different sequence, that is once as AB and once as BA, both are indicated by the same number to represent a different situation. In the factor's domain between both conditions the separation will go through a situation of co-elution or Rs = 0. When modelling the above, the different situations AB and BA are not distinguished and no model will pass through zero in the intermediate domain. Thus to distinguish between both situations one should give one of the two resolutions a negative sign [e.g., Rs(AB) = 1.5 and Rs(BA) = –1.5]. In a study where resolution was modelled, it was reported that "almost all models for Rs had serious lack of fit problems". The reason for these problems can be easily found in the above. The optimum was then selected as the best result from the design experiments. There is nothing wrong with that approach, but then one does not use all the available information.
Second, only the resolution between consecutive peaks is of interest to find the best conditions. However, the problem is that because elution sequence changes occur between design experiments, one does not know which peak pairs are relevant at a given set of conditions. Consequently, one should model the resolution between all possible peak pairs. This means 15 models for a mixture with six compounds and 78 models for a mixture of 13 compounds. Such modelling becomes tedious, while a majority of models will in fact be redundant. For the two reasons above one does better not to model resolution (or selectivity factor) during separation optimization.
Alternatively, the retention times (and occasionally the peak widths) will be modelled. This approach requires one (occasionally two) models for each compound. Peak widths are also modelled for isocratic separations, while for gradient elution one observes from the measured peak widths whether they can be considered constant or not and thus don't need to be modelled. Then the relevant resolutions are calculated from the modelled responses for given experimental conditions, because;

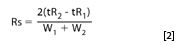
where tRi and Wi are the retention times and baseline peak widths of two adjacent peaks.
In a DoE approach a quadratic model (Equation 1) is usually built. In a number of publications the results of replicated experiments (e.g., at centre point level) are used to estimate experimental error and to determine which coefficients of the model are non-significant (i.e., equal to zero). Very often nothing is done with the observed results. Normally a new model without the non-significant terms should then be build. However, when one uses either the first model or the second to select the optimal conditions, it will not make a large difference. The models determine regions with proper response characteristics. When considering the region determined by the full quadratic model, one does not expect the selection to be largely changed from a model modelling the same data but where the non-significant contributions to the model are eliminated.
Often in method optimization the appropriate conditions are visually derived from the response surfaces or the equivalent contour plots (Figure 1). These are visualizations of the quadratic model that has been built. Now when examining three factors, one has to fix one factor at a given value to be able to visualize a part of the entire response surface. This is similar to selecting a chromatogram from an LC–DAD measurement.


Figure 1: Response surface and its corresponding contour plot, representing the behavior of a response as a function of two factors.
The chromatogram selected at low wavelength does not necessarily resemble that at an intermediate or at a high wavelength. Each of them only shows a tiny part of the entire data set. The response surfaces observed at low, intermediate and high fixed value of the third factor also do not necessarily resemble each other and they also each show a fraction of the entire response surface. When evaluating four, five or six factors in an optimization step, one has to fix two, three or four factors to be able to draw a response surface for the two remaining. The more factors that need to be fixed the smaller the fraction of the entire response surface one is visualizing and observing. In fact one does not have an idea whether the observed best conditions represent a local optimum, which can be far away from the global one, or not.
Now when considering our specific problem of separating a mixture of compounds, we will not determine the optimum from the response surface visualization because only models for retention time (and occasionally for peak width) are available. To find the conditions where the worst separated peak pair is separated best, a grid over the entire domain is considered. This approach is explained in detail in references 5 and 6. For each factor in its examined interval a feasible step size is defined. For example, for percentage of modifier the step size might be 1%, 2% or 5%; for the pH it could be 0.1 or 0.2 pH units. These steps determine a number of feasible levels within the factor range, for example 20 for %modifier and 30 for the pH. The above grid is composed of all combinations of the different factor levels. For example, for pH and modifier in the above example, the grid contains 600 points (i.e., 20 × 30). When four or more factors are considered, easily ten- or hundred thousands of grid points are obtained, which makes the calculation work tedious. Occasionally then broader steps can be considered resulting in fewer grid points.
At each grid point one predicts the retention time of a given compound from the model built and considers its corresponding width. The retention times (with their widths) are then sorted from high to low (representing consecutive peaks) and the resolutions between consecutive peaks are calculated. By this approach only the relevant resolutions are considered. At each point the smallest of these resolutions is selected because it represents the worst separated peak pair at that set of conditions. From all minimal resolutions one can derive the different conditions where the worst separated pair is best separated or where it is baseline separated, Rs > 1.5. This approach leads to the indication of the conditions were best separations are predicted. It does not require any visualization but indicates the proper optimum, even for higher numbers of examined factors, though there the calculation load is high. The predicted separation at the selected set of conditions is then verified experimentally.
The following recommendation can be given from a practical point of view to separate mixtures with a considerable number of compounds (e.g., in drug impurity profiles), and regards the gradient or solvent strength conditions: When measuring experimental design results to apply an approach as described above, take care to choose the initial gradient or solvent strength conditions such that the elution time differences between the first and last eluting peaks are large enough. If not, one risks performing lots of calculations and ending up with best conditions where not all peaks are baseline separated. Speeding up the analysis once baseline separation is obtained belongs to the fine tuning of the method and can be done rather quickly in different ways (e.g., gradient adaption, flow-rate changes, column dimension changes), while a repetition of the experimental design conditions at an adapted gradient is much more tedious.
Yvan Vander Heyden is a professor at the Vrije Universiteit Brussel, Belgium, department of Analytical Chemistry and Pharmaceutical Technology, and heads a research group on chemometrics and separation science.
References
1. B. Dejaegher and Y. Vander Heyden, LCGC Europe, 20(10), 526–532 (2007).
2. B. Dejaegher and Y. Vander Heyden, LCGC Europe, 21(2), 96–102 (2008).
3. B. Dejaegher and Y. Vander Heyden, LCGC Europe, 22(5), 256–261 (2009).
4. B. Dejaegher and Y. Vander Heyden, LCGC Europe, 22(11), 581–585 (2009).
5. B. Dejaegher, M. Dumarey and Y. Vander Heyden, LCGC Europe, 23(4), 218–224 (2010).
6. B. Dejaegher, M. Dumarey and Y. Vander Heyden, LCGC Europe, 23(10), 536–542 (2010).
















Separating Impurities from Oligonucleotides Using Supercritical Fluid Chromatography
February 21st 2025Supercritical fluid chromatography (SFC) has been optimized for the analysis of 5-, 10-, 15-, and 18-mer oligonucleotides (ONs) and evaluated for its effectiveness in separating impurities from ONs.


