The Role of Surface Coverage and Orthogonality Metrics in Two-Dimensional Chromatography
LCGC Europe
The enhanced separation power of two-dimensional (2D) chromatography has become accessible thanks to the commercialization of dedicated two-dimensional systems. However, with great separation power comes great system complexity. All two-dimensional systems require a means for collecting and transferring fractions of the first dimension to the second dimension typically via a loop-based interface in on-line methods. It is important to collect a sufficient number of fractions to prevent loss of the first dimension resolution; that is, the sampling rate must be sufficient to prevent undersampling. Another key parameter to consider is selectivity. By coupling two selectivities that have unrelated retention mechanisms we are able to exploit the different physiochemical characteristics of the sample we wish to separate. This is the concept behind the term orthogonality. By coupling orthogonal selectivities and reducing under‑sampling, our system should be able to achieve the theoretical maximum two-dimensional peak


Photo Credit: zffoto/Shutterstock.com

Michelle Camenzuli, Centre for Analytical Sciences in Amsterdam (CASA), Analytical Chemistry group, Van ’t Hoff Institute for Molecular Sciences, University of Amsterdam, Amsterdam, The Netherlands
The enhanced separation power of two-dimensional (2D) chromatography has become accessible thanks to the commercialization of dedicated two-dimensional systems. However, with great separation power comes great system complexity. All two-dimensional systems require a means for collecting and transferring fractions of the first dimension to the second dimension typically via a loop-based interface in on-line methods. It is important to collect a sufficient number of fractions to prevent loss of the first dimension resolution; that is, the sampling rate must be sufficient to prevent undersampling. Another key parameter to consider is selectivity. By coupling two selectivities that have unrelated retention mechanisms we are able to exploit the different physiochemical characteristics of the sample we wish to separate. This is the concept behind the term orthogonality. By coupling orthogonal selectivities and reducing underâsampling, our system should be able to achieve the theoretical maximum two-dimensional peak capacity. Unfortunately, this is virtually impossible to achieve with current technology. It follows that it is important to be able to calculate the actual (conditional) peak capacity of our two-dimensional chromatographic system. To calculate this, we need to know the first dimension sampling time and the proportion of the separation space occupied by peaks; the latter is referred to as surface coverage. This review discusses the role of orthogonality metrics and surface coverage metrics and their relationship to selectivity and peak capacity in two-dimensional chromatography.
Setting up a two-dimensional (2D) chromatographic system involves more than building a system that uses two columns to separate a sample into its components. To achieve this effectively, an understanding of the concept of dimensionality in chromatography is required.
There are three key aspects to this concept: sample dimensionality, apparent sample dimensionality, and the system dimensionality (1). The relationship between these concepts is illustrated in Figure 1. All of these aspects should be considered when setting up a 2D system. The first aspect, sample dimensionality, refers to the number of independent factors that can be used to characterize or separate the sample (1). For example, the number of carbon units in the structure of the various sample components is a factor that can be used to describe or separate the components of a sample of alkyl benzenes.

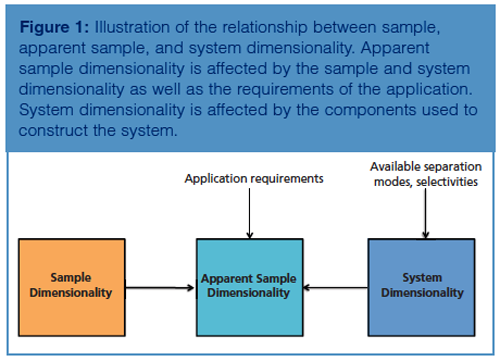
For a sample containing a mixture of proteins, sample components could be defined by their molecular weight, their isoelectric point, or their affinity for a certain antibody for example. Each factor that can be used to characterize the individual components of the sample is regarded as one dimension. It follows that the protein sample mentioned above can be described as multidimensional whereas the alkyl benzene sample is one-dimensional. The apparent sample dimensionality follows the same logic as described above. However, it refers to the number of factors that the analyst is interested in or are actually used to separate the sample into its components (1). For example, if we again consider a mixture of proteins, and the molecular weight was the only property used to separate the sample components, then the apparent sample dimensionality would be one, even though the sample itself is multidimensional.
When the sample dimensionality is understood, the various factors of this dimensionality should be considered when choosing appropriate separation techniques or retention mechanisms to combine to build the 2D system most appropriate for exploiting the sample dimensionality. In other words, the system dimensionality should be appropriate for the (apparent) sample dimensionality. System dimensionality is defined as the number of different separation stages where different retention mechanisms are employed (1). For example, a chromatographic system employing a C18 column and an ion exchange column would be considered 2D since it incorporates two separation stages with two different retention mechanisms. Conversely, a system comprised of two C18 columns using the same mobile phase for both dimensions could be considered a one-dimensional (1D) system, despite the involvement of two columns since both dimensions would separate the sample based primarily on hydrophobicity. Such a system would essentially be equivalent to a long C18 column. It should be noted that the stationary phase selectivity in each dimension is not the only factor that can determine whether the system is one-dimensional or multidimensional: the mobile phases used in each dimension play an equally important role. For example, a two-dimensional system can consist of two C18 columns when mobile phases are used to generate a selectivity difference in each dimension, if the sample itself is multidimensional. Such is the case for peptides, which can be separated based on hydrophobicity, size, and charge. The latter property was exploited by employing an acidic mobile phase (pH 2.6) in the first dimension and a basic mobile phase (pH 10) in the second dimension with both dimensions using C18 stationary phases (2). In acidic mobile phase conditions, acidic peptides (pKa 3 or below) would be protonated and therefore retained on the C18 stationary phase, whilst “neutral” and basic peptides (pKa above 7) would be ionized, consequently having reduced retention. In basic conditions, the reverse is true. This system produced greater separation power, in terms of practical peak capacity, compared to the commonly used reversed phase × strong cation exchange 2D system.
It follows that when setting up an appropriate 2D system for a particular sample, the analyst chooses the appropriate separation mechanisms (stationary phase and mobile phase) to exploit the dimensionality of the sample. Such a system would have one dimension of the system exploiting one aspect of the sample dimensionality and a second dimension that makes use of another aspect of the sample dimensionality. Ideally, there would be no overlap between the sample dimensions that the system dimensions exploit. Such a system would be considered orthogonal. An orthogonal 2D system could approach the theoretical maximum peak capacity, which is the product of the peak capacities in the first and second dimension (1,3).
Orthogonality and Selectivity in Two-Dimensional Chromatography
While it is known that maximum separation power-in terms of peak capacity-can be achieved by selecting orthogonal selectivities for the first and second dimension, it is not always a simple process to choose appropriate selectivities. Many stationary phases share a certain degree of similarity between their retention mechanism and the retention mechanism of other stationary phases. This is particularly the case when combining reversed-phased liquid chromatography phases in a 2D system. For example, it is possible to use a cyano column and a C18 column for the separation of coffee and still achieve a reasonable degree of orthogonality because the cyano column is capable of participating in π-π interactions with the aromatic components of coffee (4,5). However, the cyano stationary phase is also capable of interacting with solutes based on their degree of hydrophobicity, which is a retention mechanism it has in common with the C18 stationary phase. While these two selectivities exploit two different sample dimensions and form a system with a dimensionality equal to 2 according to the theory of Giddings (1), the system is not completely orthogonal and the theoretical maximum peak capacity cannot be equated to the actual peak capacity. It follows from this example that orthogonality is not a binary “yes or no” concept. Rather, orthogonality comes in degrees and cannot be entirely predicted by coupling two systems that in principle separate with different retention mechanisms. This is where orthogonality metrics become useful. These metrics allow chromatographers to assess how effectively their chosen selectivities distribute sample components throughout the 2D separation space. It has been argued that experienced chromatographers can adequately assess orthogonality themselves, without using metrics. While this is true to a degree, it should be appreciated that orthogonality metrics provide an assessment unbiased by user inclinations or dayâtoâday variability and this makes them particularly valuable for inclusion in industrial quality assurance. In addition, orthogonality metrics can serve as a guide to help the analyst keep track of the success of their method development procedures. For example, an analyst may be testing a number of different selectivities to determine which will give the most optimal 2D system for their particular sample. By calculating the orthogonality for each selectivity couple, they can gain a better understanding of the physiochemical aspects that play a role in separating the sample. This may lead to the selection of columns whose retention mechanisms target these physiochemical properties, eventually leading to the development of the most orthogonal system possible for their sample.
There are a wide range of orthogonality metrics. Most of these were recently compared by Schure and Davis (6). Their study compared the assessment of 20 orthogonality metrics applied to 47 experimental chromatograms. The assessments of the orthogonality metrics were compared to those given by expert reviewers who assessed the chromatograms visually based on their experience in 2D chromatography. A couple of important key points from this study include the observation that while the expert reviewers agreed on which were the best and which were the worst chromatograms, their assessment on the “mediocre” chromatograms were variable. This implies that the value of orthogonality metrics is their ability to provide constant, reliable assessments of orthogonality throughout the range of possible degrees of orthogonality. The other important point from their study was that no single metric stood out as the best for assessing orthogonality. Methods reporting metrics that appeared as good indicators of orthogonality included the convex hull, dimensionality, and information theory. Recently developed metrics that were not tested in the study of Schure and Davis were the asterisk equations (7) and the maximal information coefficient (8). In the interests of conciseness, we will briefly discuss the convex hull, dimensionality, asterisk, maximal information coefficient, and the bin counting methods. The latter have proven very popular in chromatography.
The bin counting methods are intuitive, simple to use, and are effective in assessing the orthogonality of 2D separations. There are two versions of the bin counting methods that are conceptually very similar (2,9). Both methods divide the separation space into boxes or bins, where the number of bins equals the number of components within the sample. The width of the peaks corresponds to the average peak width. In the original method, the number of bins containing peaks is summed up and compared with the total number of bins via equation 1 (2):

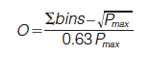
[1]
Where Pmax is the total number of bins. O = 1 for an orthogonal separation based on the observation that systems close to orthogonal have a ratio of bins occupied or total bins = 0.63. Bins are also summed up in the second version of the bin counting methods (9). The difference between this method and the original one is that firstly a “fence” is drawn around the area containing bins with peaks. The bins within this enclosed area are summed whether they have peaks or not. The number of bins within the enclosure is compared to the total number of bins to produce the value of orthogonality. Again, this value will range from 0 for a nonorthogonal system and reach a maximum of 1 for a fully orthogonal system where each bin contains one peak (9). While these methods are intuitive and easy to implement, the key limitation that they face is the necessity to know the number of components within the sample. This is not always possible for complex samples, such as protein digests. The consequence is that an insufficient number of bins may be used causing an inflated value of orthogonality. Alternatively, using too many bins will artificially deflate the value of orthogonality.
Dimensionality as an orthogonality metric also uses bins to divide the separation space into sections. Yet unlike the bin counting method described above, it is not necessary to know the number of sample components. The size of the bins or intervals are scaled relative to the first eluting and last eluting peaks in the dimension being considered, using equation 2 (10):

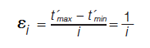
[2]
Where εi is the interval width, t’max and t’min are the normalized retention times for the last and the first eluting peak, respectively. Retention times are normalized as per equation 3 (10), which is the first step in calculating orthogonality for most-if not all-metrics.

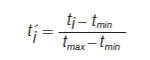
[3]
t’i is the normalized retention time of peak i, ti is the retention time of peak i, and tmin and tmax are the retention times of the first and last eluting peaks, respectively. It follows that the normalized separation space would range from 0 to 1 on each axis or dimension hence the 1/i in equation 2. The value i in equation 2 varies in value from 1 up to some maximum value. The number (N) of bins or intervals required to cover the separation space at a given interval width is determined by the user. A plot of log N versus log εi is constructed and in the least squares regression slope of the plot is multiplied by -1 to give the value of dimensionality (D) (10). For a 2D separation, the width of the intervals varies with respect to both dimensions. A completely orthogonal 2D separation gives a value of 2.00. Conversely, a nonorthogonal separation would give a value of 1.00 for D indicating that the separation is in fact 1D in agreement with the Giddings concept of dimensionality discussed earlier (10). One limitation of the dimensionality orthogonality metric is apparent when insufficient data is distributed throughout the separation space. To compensate for this the user can include a “step” value within the value of i so that the corresponding log N versus log εi plot is more smooth, improving the reliability of the calculation of D (10). User defined variables such as i in this method can introduce a source of variability into the reported metric, which is undesirable when different users are comparing orthogonality values. Recently another orthogonality metric that also scales the bin width was developed; in this case by changing the grid resolution. The method is almost identical to the method of Zeng, Hugel, and Marriott (11) with the exception that the maximal informational coefficient (MIC) is used in place of the least squares linear regression coefficient (R2). The metric for orthogonality using the MIC is calculated via equation 4 (8).

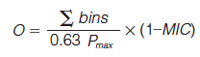
[4]
Where ∑bins is the sum of bins containing peaks and Pmax is the maximum theoretical peak capacity according to Giddings’s theory (1). The authors put forward MIC as a replacement for R2 on the basis that it considers nonlinear correlation as well as linear correlation. While it was shown that using equation 4 with MIC rather than R2 improved the method (8), they did not compare this metric with other metrics nor did they investigate the effect of the number of sample components on O, which is known to affect almost all orthogonality metrics.
There are a number of metrics that do not require the use of bins or intervals. The convex hull is one of them (12). There are numerous types of convex hulls but they all share the same concept: a polygon of the smallest possible size is used to fence the area containing peaks. Naturally the fenced area will contain some portion of the separation space that does not contain peaks, which may add some bias to the reported value of orthogonality. Some versions of the convex hull, such as the α-hull and the local convex hull, require some user input in setting certain parameters that govern the size of the hull (12). Another metric that does not require the division of the separation space is the asterisk equations (7). These equations are based on the distance of peaks from 4 lines that cross over the separation space and act as a reference rather than creating divisions as illustrated in Figure 2.

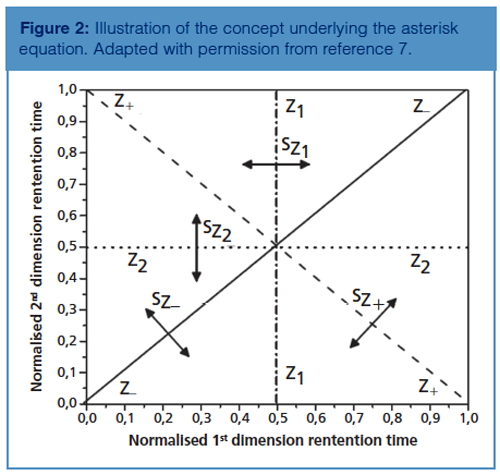
The standard deviation of the distances of every peak from each Z line is determined using equations 5–8 (7).

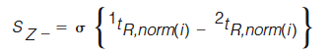
[5]

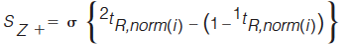
[6]

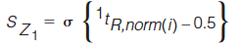
[7]

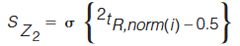
[8]
In equations 5–8, the expression in the curly brackets calculates the distance of peak, i, from the Z line in question, the standard deviation of these distances is determined as indicated by the σ outside the curly brackets. 1tR,norm(i) and 2tR,norm(i) are the normalized retention times for peak i in the first and second dimension, respectively. Retention times are normalized using equation 3. To express the resulting standard deviation of distances on the same scale for all Z lines, these S values are transformed to Z values using equations 9–12 (7).


[9]

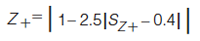
[10]

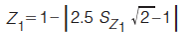
[11]

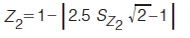
[12]
Because the Z values range from 0 to 1, they can readily be reported as a percentage. Each Z value describes the degree of clustering with respect to that line. This can be used to pinpoint regions of the separation space that have a relatively high degree of clustering of peaks. The Z values are combined in equation 13 to give the metric for orthogonality, AO (7).

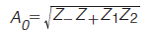
[13]
Since the Z values are reported as a percentage, it follows that AO ranges from 0 to 100% where a value of 100% indicates a completely orthogonal 2D separation. The benefits of the asterisk equations are that they are easy to implement in simple spreadsheet software such as Microsoft Excel, they are intuitive, they are not biased by user defined parameters, and it is not necessary to know the number of sample components. That said, one limitation of this method is that AO is supressed when there are equal to or less than 25 peaks in the separation (7). In such cases it should only be used to compare chromatograms for the one sample with different conditions in a qualitative manner.
Surface Coverage and its Relationship with Orthogonality
There are numerous metrics for surface coverage (2,9,12) and orthogonality (2,7,8,10,13–23). Conceptually, they are related. If two selectivities are combined that produce a nonorthogonal separation for a given sample then the surface coverage will be reduced compared to that of an orthogonal separation for the same sample. Consequently, surface coverage metrics can be used to report orthogonality. That being said the reverse is generally accepted as not valid. This is because orthogonality metrics generally only consider the degree of similarity of the selectivities of the two dimensions. On the other hand, surface coverage metrics consider the distribution of peaks within the separation space in a geometric manner. This gives us an idea of the proportion of space that is accessible by sample components and therefore peaks. For example, the asterisk equations and dimensionality metric discussed above describe the distribution of peaks throughout the separation space but do not describe the proportion of space accessed by peaks. Conversely, the convex hull and bin counting methods describe the proportion of space accessed by peaks and consequently describe the surface coverage. While the distinction between orthogonality and surface coverage does not make much difference in choosing selectivities, it does make an impact in our ability to calculate the actual peak capacity of a 2D system. In practice the actual peak capacity of a comprehensive 2D system, known as the conditional peak capacity (no’c,2D), is given by equation 14 (24).

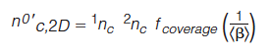
[14]
Where 1nc and 2nc denote the peak capacity of the first and second dimension, respectively. This equation considers the two practical aspects that limit us from achieving the theoretical peak capacity: coverage of the separation space by peaks (fcoverage) and undersampling of the first dimension (<β>). Since fcoverage describes the proportion of the separation space that is accessible to peaks, it follows that surface metrics can act as fcoverage in equation 14 so long as they range in value from 0 to 1 as is required in the equation. The undersampling parameter <β> is given by equation 15 (24).

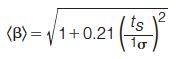
[15]
Where ts is the first dimension sampling time and 1σ is the peak standard deviation in the first dimension prior to sampling. It follows that this value must be an average across all peaks since there is only one value for <β> in equation 14. While orthogonality metrics are useful for assessing the various combinations of selectivities to construct an optimal 2D system, if calculating peak capacity is important for your application then surface coverage metrics are useful.
Conclusion
Ideally the peak capacity of a 2D chromatographic system should equate to the product of the peak capacities of the first and second dimension. In reality this is virtually impossible to achieve. Two key limitations preventing many 2D separations from achieving ideal peak capacity are undersampling of the first dimension and the ability of the system to allow peaks to evenly distribute throughout the separation space. The former is relatively well understood and can be accounted for in the computation of the conditional 2D peak capacity using the sampling time. The ability of the system to distribute peaks evenly throughout the separation space is not so easily accounted for. Surface coverage metrics can be used to determine the proportion of separation space accessible to peaks. These metrics typically consider the distribution of peaks relative to the total separation space without accounting for the effect of peak width on consuming separation space. However, if the goal is to screen a number of selectivities to gauge which combination will provide the most optimum 2D separation then orthogonality metrics are useful.
Acknowledgements
The author would like to acknowledge Dr. Alina Astefanei and Dr. Andrea Gargano for their insightful comments during the editing phase of this manuscript. The following institutions are acknowledged for their financial contributions regarding the asterisk equations (part of the HYPERformance LC×LC project) mentioned in this review: Akzo Nobel, Avantor, DSM, RIKILT, Shell, Syngenta, Thermo Fisher Scientific, TNO, University of Amsterdam, and the University of Groningen.
References
- J.C. Giddings, J. Chromatogr. A. 703, 3–15 (1995).
- M. Gilar, P. Olivova, A.E. Daly, and J.C. Gebler, Anal. Chem.77, 6426–34 (2005).
- J.C. Giddings, Anal. Chem. 56, 1258A–1260A, 1262A, 1264A passim (1984).
- M. Mnatsakanyan, P.G. Stevenson, D. Shock, X.A. Conlan, T.A. Goodie, K.N. Spencer, et al., Talanta82, 1349–1357 (2010).
- M. Mnatsakanyan, P.G. Stevenson, X.A. Conlan, P.S. Francis, T.A. Goodie, G.P. McDermott, et al., Talanta82, 1358–1363 (2010).
- M.R. Schure and J.M. Davis, J. Chromatogr. A.1414, 60–76 (2015).
- M. Camenzuli and P.J. Schoenmakers, Anal. Chim. Acta.838, 93–101 (2014).
- A. Mani-Varnosfaderani and M. Ghaemmaghami, J. Chromatogr. A.1415, 108–114 (2015).
- M. Gilar, J. Fridrich, M.R. Schure, and A. Jaworski, Anal. Chem.84, 8722–8732 (2012).
- M.R. Schure, J. Chromatogr. A.1218, 293–302 (2011).
- Z.-D. Zeng, H.M. Hugel, and P.J. Marriott, Anal. Chem.85, 6356–63 (2013).
- S.C. Rutan, J.M. Davis, and P.W. Carr, J. Chromatogr. A. 1255, 267–76 (2012).
- Z. Liu and D. Patterson Jr, Anal. Chem. 67, 3840–3845 (1995).
- P.J. Slonecker, X. Li, T.H. Ridgway, and J.G. Dorsey, Anal. Chem.68, 682–689 (1996).
- J.W. Dolan, A. Maule, D. Bingley, L. Wrisley, C.C. Chan, M. Angod, et al., J. Chromatogr. A.1057, 59–74 (2004).
- E. Van Gyseghem, I. Crosiers, S. Gourvénec, D.L. Massart, and Y. Van der Heyden, J. Chromatogr. A. 1026, 117–128 (2004).
- E. Van Gyseghem, M. Jimidar, R. Sneyers, D. Redlich, E. Verhoeven, D.L. Massart, et al., J. Chromatogr. A. 1042, 69–80 (2004).
- P. Forlay-Frick, E. Van Gyseghem, K. Héberger, and Y. Van der Heyden, Anal. Chim. Acta.539, 1–10 (2005).
- U.D. Neue, J.E. O’Gara, and A. Méndez, J. Chromatogr. A.1127, 161–174 (2006).
- C. West and E. Lesellier, J. Chromatogr. A.1203, 105–113 (2008).
- R. Al Bakain, I. Rivals, P. Sassiat, D. Thiébaut, M.C. Hennion, G. Euvrard, et al., J. Chromatogr. A.1218, 2963–2975 (2011).
- W. Nowik, M. Bonose, S. Héron, M. Nowik, and A. Tchapla, Anal. Chem.85, 9459–9468 (2013).
- W. Nowik, S. Héron, M. Bonose, M. Nowik, and A. Tchapla, Anal. Chem.85, 9449–9458 (2013).
- D.R. Stoll, X. Wang, and P.W. Carr, Anal. Chem.80, 268–278 (2008).
Michelle Camenzuli is a tenure-track assistant professor within the analytical chemistry group at the University of Amsterdam, The Netherlands. At the moment her research is primarily focused on developing new methods and column technology for proteomics. In 2014 she completed a 1-year postâdoctorate focused on orthogonality in two-dimensional liquid chromatography with Peter Schoenmakers at the University of Amsterdam. During her post-doctorate she developed a new metric for orthogonality known as the asterisk equations. Camenzuli currently has 20 publications in peer-reviewed journals and one patent for reaction flow chromatography.
















A Novel Two-Step Workflow for Extracting Clean Mass Spectra in LC×LC–HRMS Data
March 3rd 2025LCGC International spoke to Paul-Albert Schneide and Oskar Munk Kronik about the development and application of a novel two-step workflow—mass filtering (MF) combined with multivariate curve resolution (MCR)—for extracting clean mass spectra from trace-level compounds in LC×LC–HRMS data.


