Analyzing Small Molecule Metabolite Profiles of Diabetic and Nondiabetic Urine Samples Using GCXGC–TOF-MS and Statistical Software as a Data-Mining Strategy
Special Issues
Two-dimensional gas chromatography–time-of-flight mass spectrometry (GCÃ-GC–TOF-MS) analysis has emerged as one of the technologies of choice for the analysis of small metabolite profiles. The results of these analyses produce substantial quantities of data that can be extremely time-consuming and labor-intensive for the analyst to interpret. New software provides a tool for the scientist to use as a data-mining strategy to find significant results from large, complex data sets. This proof of concept research was conducted using comprehensive GCÃ-GC–TOF-MS to elucidate the small-molecule metabolite profiles of diabetic and nondiabetic urine in search of key differences between disease-state and nondisease-state individuals.
Small-molecule metabolite analysis presents challenges that historically have relied heavily upon standard quadrupole gas chromatography–mass spectrometry (GC–MS) utilizing targeted methods of selected ion monitoring and MS-MS mass spectrometric techniques. The complex nature of metabolomic samples demands analytical solutions and instrumental methods that will identify the small molecule metabolite profile completely as well as discover significant key components of interest.
Following two-dimensional (GC×GC)–time of flight (TOF)-MS, the data processed diabetic and nondiabetic samples were analyzed by proprietary software.
Experimental
This research was designed to study trimethylsilyl-derivatized urine samples for the small molecule metabolite profile intended to detect possible chemical variations between diabetic disease state and normal control nondiabetic subjects. The experimental design for this study involved sample preparation with extraction and derivatization followed by GC×GC–TOF-MS analysis and data processing to generate sample peak tables. Next a comparison analysis was performed (Statistical Compare function of ChromaTOF software, LECO, St. Joseph, Michigan), and Fisher ratios were calculated for all components in the compound table. The data results were refined to eliminate background from column bleed or derivatization matrix. The 619 analytes with the largest Fisher ratio values were exported as a .csv file and were used in a multivariate analysis (1).
Morning fast urine samples were collected from four subjects: two nondiabetic normal controls, one type I diabetic, and one type II diabetic. Samples were stored under refrigeration at 4 °C before liquid–liquid extraction with methylene chloride and derivatization with N,O-bis-(trimethylsilyl)-trifluoroacetamide (BSTFA). Six 10-mL aliquots from each subject were prepared by acidification with concentrated sulfuric acid to pH 2. Aliquots (10 mL each) were extracted with 2 mL of methlyene chloride into a 20-mL scintillation vial containing approximately 5 mg of sodium sulfate. Derivatization was carried out with BSTFA by placing 200 μL of extract into a sealed 2-mL autosampler vial containing approximately 0.5 mg of sodium sulfate. A 30-μL aliquot of dry pyridine was added to the vial. A 200-μL aliquot of BSTFA was added to each vial. The samples were heated to 60 °C for 1 h and then analyzed.
GC×GC–TOF-MS results were generated with a Pegasus 4D time of flight mass spectrometer (LECO). The mass spectrometer was equipped with an Agilent 7890 gas chromatograph (Agilent Technologies, Santa Clara, California) featuring a two-stage cryogenic modulator and a secondary oven (LECO). The software mentioned earlier was used for all acquisition control, data processing, and Fisher ratio calculations. A 30 m × 0.25 mm, 0.25-μm film thickness Rtx-5ms GC capillary column (Restek Corp., Bellefonte, Pennsylvania) was used as the primary column for the GC×GC–TOF-MS analysis. In the GC×GC configuration, a second column (1.5 m × 0.18 mm, 0.18-μm film thickness, Restek Corp.) was placed inside the secondary GC oven after the thermal modulator. The helium carrier gas flow rate was set to 1.5 mL/min at a corrected constant flow via pressure ramps. The primary column was programmed with an initial temperature of 40 °C for 1.00 min and ramped at 6 °C/min to 290 °C for 10 min. The secondary column temperature program was set to an initial temperature of 50 °C for 1.00 min and then was ramped at 6 °C/min to 300 °C with a 10 min hold time. The thermal modulator was set to +25 °C relative to the primary oven and a modulation time of 5 s was used. The MS mass range was 45–800 m/z with an acquisition rate of 200 spectra/s. The ion source chamber temperature was set to 230 °C and the detector voltage was 1750 V with electron energy of -70 eV.


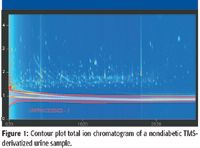
Figure 1
Results and Discussion
Results of the diabetic versus nondiabetic small molecule metabolite profile study by GC×GC–TOF-MS analysis are shown in Figures 1 and 2. The total ion chromatograms are depicted as contour plots. These chromatographic examples show visual peak differences between diabetic and nondiabetic sample types. Figures 1 and 2 illustrate the increased peak capacity, improved analyte detectability, and enhanced resolution gained by GC×GC–TOF-MS (2). On average, over 1000 peaks were found per sample with a signal to noise ratio of 100 or greater for this study. The red cross-hatched area in each contour plot is an unprocessed region developed in the Classifications feature of the software, which eliminates unwanted background peaks.


Figure 2
Analysis
A method using the Statistical Compare software feature was applied to 24 samples in two classes, diabetic and nondiabetic. Peak table alignment was performed for all of the sample peak tables, followed by generation of statistics for all analytes found. A compound table was generated from the 24 aligned peak tables. Statistical parameter comparisons were then viewed in the software to facilitate evaluation and assessment between the two classes. The goal of using this software was to apply the Statistical Compare feature so that significant conclusions of analytical importance can be developed from complex sets of data. The compound table was sorted from highest to lowest Fisher ratio. The top 619 analytes sorted by their Fisher ratio values were exported as .csv file into a multivariate analysis program. The compound table shown in Figure 3 lists the top 20 analytes by the highest Fisher ratio values. The columns listed in the compound table are the analyte number, analyte name, average retention time, average peak area and the fisher ratio for each analyte. Statistical parameters of interest can be set in the properties tab of the compound table by the user.


Figure 3
Fisher Ratio Results
A Fisher ratio was calculated for all of the analytes found in the compound table. The Fisher ratio method is used to discover the unknown chemical differences among known classes of complex samples. The numerical value of the Fisher ratio is related to the degree of variance by the size of the number. The higher the Fisher ratio numerical value, the greater the class variance is for a particular compound. The Fisher ratio plot shown in Figure 4 illustrates the graphical representation of the Fisher ratios calculated for each analyte from the completed statistical compare process. The x-axis is the retention time. The y-axis is the numerical value of the Fisher ratio. Each Fisher ratio intensity is labeled with the corresponding analyte number from the compound table. It is easy to identify visually the compounds that exhibit the highest variance.


Figure 4
Data Export as a .csv File Utilized in Multivariate Analysis
The raw data for the analytes of interest can be exported as a .csv file for use in peripheral data reduction software. All of the required fields of interest need to be displayed in the compound table. The software will include only the visible fields in the export. There is one exception, which is a class column that will be added to each sample column. It is possible to export all or selected analytes from the compound table. The .csv file of the diabetic versus nondiabetic small molecule metabolite profile data was exported as an Excel spreadsheet displaying the analyte peak name, sample name, class, and peak area for every sample, analyte, and class included from the software analysis. The columns shown in Figure 5 represent the partial .csv file results of what statistical information were set to be displayed in the compound table. This .csv file was designed to be used in a commercially available peripheral multivariate analysis program.

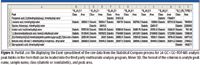
Figure 5
The exported .csv file was subsequently loaded as a spreadsheet containing the top 619 analytes according to their Fisher ratio into the program mentioned earlier. The data was submitted to an eigenvector analysis prior to PCA. Multivariate PCA analysis was conducted on the variables of analyte identification, class, (diseased or nondiseased), and analyte peak area. Following PCA analysis, K-means clustering was applied using the software program mentioned above. The results from the software exported as a .csv file with PCA and clustering analysis are shown in Figure 6 by the two-dimensional PCA plot. Each colored triangle in the graph represents a different metabolite. The graph plotted PCA 1 on the x-axis and PCA 3 on the y-axis. The goal for this proof-of-concept research was to find analytes that are unique to either diabetic or nondiabetic classes. The graph shows four groups of analytes labeled A, B, C, and D enclosed by blue ovals. These analytes were found to be unique groups of specific interest. Group A analytes designated by red triangles were found to be analytes found only in the nondiabetic controls. Group B analytes designated by the light green triangles were found to be unique to the Type II diabetic individual. The lone Group C analyte was found to be unique to both diabetic individuals. The two analytes in Group D were found only in the Type I diabetic individual. These findings demonstrate the value of the software, Fisher ratios, and multivariate analysis to assist in data mining and are meant to be proof of concept only and not for implication of any scientific significance.


Figure 6
Conclusion
This article presents a data-mining strategy using diabetic versus nondiabetic GC×GC–TOF-MS metabolomic analysis followed by statistical comparison and Fisher ratios as well as data results exported to peripheral multivariate software to define small molecule metabolite profile differences. A comprehensive GC×GC-TOF-MS analysis accompanied by statistical comparison targeting high-variance data through Fisher ratios along with multivariate PCA and clustering analysis was demonstrated. This exploratory research presents an optimized GC×GC–TOF-MS analysis followed by a data-mining strategy using preliminary statistical methods and multivariate analysis to identify significant metabolite variation in complex biological samples from distinct classes.
The results presented from this study demonstrate that significantly increased analytical performance is achieved by utilizing comprehensive GC×GC–TOF-MS for the characterization of small molecule metabolite profiles. TOF-MS provides the nonskewed mass spectra and fast acquisition needed to deconvolute complex overlapping peaks as well as the data density required to characterize the narrow peaks (<100 ms) GC×GC can generate. Software was used to align a large set of data and define the highest variance for analytes between disease and nondisease state subjects. Furthermore, it was demonstrated that the results from can be exported quite simply into multivariate analysis programs whereby PCA and clustering analysis can be applied with the purpose of providing significant results and possible biomarker discovery.
John Heim is with LECO Corporation, St. Joseph, Michigan.
References
(1) K.M. Pierce, J.C. Hoggard, J.L. Hope, P.M. Rainey, A.N. Hoofnagle, R.M.Jack, B.W. Wright, and R.E. Synovec, Anal. Chem. 78(14), 5068–5075 (2006).
(2) L. Mondello, P.Q. Tranchida, P. Dugo, and G. Dugo, Comprehensive Two-Dimensional Gas Chromatography-Mass Spectrometry: A Review Published online 31 January 2008 in Wiley InterScience (www.interscience.wiley.com) DOI 10.1002/mas.20158













Thermodynamic Insights into Organic Solvent Extraction for Chemical Analysis of Medical Devices
April 16th 2025A new study, published by a researcher from Chemical Characterization Solutions in Minnesota, explored a new approach for sample preparation for the chemical characterization of medical devices.


Sorbonne Researchers Develop Miniaturized GC Detector for VOC Analysis
April 16th 2025A team of scientists from the Paris university developed and optimized MAVERIC, a miniaturized and autonomous gas chromatography (GC) system coupled to a nano-gravimetric detector (NGD) based on a NEMS (nano-electromechanical-system) resonator.

Miniaturized GC–MS Method for BVOC Analysis of Spanish Trees
April 16th 2025University of Valladolid scientists used a miniaturized method for analyzing biogenic volatile organic compounds (BVOCs) emitted by tree species, using headspace solid-phase microextraction coupled with gas chromatography and quadrupole time-of-flight mass spectrometry (HS-SPME-GC–QTOF-MS) has been developed.


A Guide to (U)HPLC Column Selection for Protein Analysis
April 16th 2025Analytical scientists are faced with the task of finding the right column from an almost unmanageable range of products. This paper focuses on columns that enable protein analysis under native conditions through size exclusion, hydrophobic interaction, and ion exchange chromatography. It will highlight the different column characteristics—pore size, particle size, base matrices, column dimensions, ligands—and which questions will help decide which columns to use.

