Agency Guidelines for Recombinant Biosimilars of Biopharmaceuticals
LCGC North America


All agencies have issued varying guidances for the approval of recombinant, biosimilars of biopharmaceuticals. However, their impact or meaning is in our understanding and that all submittals are considered on a case-by-case basis.
All agencies have issued varying guidances for the approval of recombinant biosimilars of biopharmaceuticals, and all submittals are considered on a case-by-case basis. This installment of "Focus on Biopharmaceutical Analysis" looks at the best methodologies for demonstrating their analytical comparability.
Biosimilars are a relatively recent addition to our healthcare system and potentially a great way to add value, for the benefit of patients. The first biosimilar product was approved in 2006 in Europe and in 2015 in the United States. Just as generics are similar to small molecules, biosimilars are approved as drugs that are similar to the reference, large-molecule biologic (innovator–proprietary). However, the data requirements are very different from those for generics. Biologics do not need to be identical to the reference product, but they do need to be supported by extensive analytical chemistry, structural analysis, functional assays, and chemistry, manufacturing, and control (CMC) testing. This testing needs to provide clear evidence to demonstrate biosimilarity to the reference product and may also require support from limited nonclinical and clinical data.
There are many ever-evolving guidance documents available globally to broadly indicate equivalence and chemically and biologically control the development and commercialization of products. Although the World Health Organization (WHO) has attempted to indicate the efficacy, safety, and quality standards that biosimilars must meet and maintain to gain approval, regional guidance documents also exist. The United States Food and Drug Administration (FDA) and European Medicines Agency (EMA) each have their own sets of guidance documents that a product must meet to gain approval in their respective region. Although these documents broadly seek to demonstrate the same clinical and nonclinical toxicology, scientific performance, and CMC controls, the need for specific data and its interpretation can vary from one region to another. There are excellent reviews and overviews of the overall field available via Google Scholar, some of which discuss the various analytical tools for characterizing biopharmaceuticals and biosimilars (1), and others that discuss the regulatory, clinical, and commercial considerations (2–4). There are also excellent overviews of how the FDA and other regulatory agencies have provided regulatory guidance documents through 2015, specific to biosimilars (5–7). Though such regulatory guidance documents do exist, they are not completely definitive. They do not state how much of a quantitative difference is acceptable for each of the critical quality attributes (CQA), including glycosylation, deamidation, and others. At what point do such differences become unacceptable for a biosimilar to be considered a “true” biosimilar, and the drug substance must then be considered as an entirely “new” drug entity and innovator biopharmaceutical product? As far as we know, such thorny questions are not adequately addressed in most regulatory guidelines or guidances for biosimilar products. Most agencies answer such questions with the generic answer-each submittal is decided on a case-by-case basis.
Globally, some countries have used the EMA approach to help define their own requirements, including Japan, Canada, Australia, and Korea, with the FDA issuing its own set of guidance documents in 2012. Currently, there is no global harmonization of requirements, leaving the industry to address differing standards and terminology without 100% clarity on how close the data need to be to demonstrate equivalence between the reference and biosimilar.
A recent publication summarizes much of the current situation regarding how to compare a biosimilar with its innovator cousin, and Figure 1 illustrates very nicely the quantitative (relative) differences in the amount of analytical, nonclinical, clinical pharmacology, and clinical studies data that are needed (8). As can be seen in Figure 1, the goal of the newer 351(k) pathway places increasing importance on analytical methodology. Its ultimate goal is to reduce the final amount of clinical studies necessary for the approval of a new biosimilar, ideally to the lowest level possible, thereby reducing investment levels from the biosimilar firm, as well as the time required to bring the biosimilar to market.


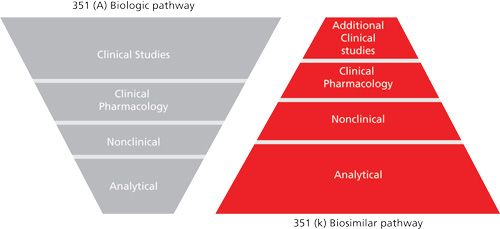
Figure 1: Schematic representation comparing top-down and bottom-up sequencing for identifying a specific protein or proteins of interest. (Adapted with permission from references 8,15.)
Generally, the type and level of testing and, more importantly, the level of biosimilarity, are not described in guidance documents. This is understandable because treatment of each clinical indication carries with it its own unique risks and benefits, and therefore each reference product is unique, requiring agencies to make a case-by-case assessment. This column installment aims to indicate the best methodologies that one should use to demonstrate analytical comparability (1).
What Constitutes a Strong Data Package?
Biosimilar analytical methods, techniques, and approaches do not have to be and cannot be identical to those of the innovator’s product. Whatever data are presented need to be interpreted in terms of the overall impact on efficacy and safety because it is the fundamental requirement to convince the regulatory agencies that any structural differences between a biosimilar and its reference product are not clinically significant. Regulatory agencies expect the biosimilar to replicate as best possible the same or analogous studies first submitted and approved for the reference product, to demonstrate true chemical equivalency between the proprietary and biosimilar products. However, that does not necessarily mean that zero differences in amino acid sequences, glycosylation patterns (qualitative and quantitative), post-translational modifications (PTMs), and higher order structures will result in regulatory approval.
This column installment relies on the various regulatory guidance documents and presents their interpretation. The discussion is limited to analytical characterization of the various CQAs. We will indicate the best current analytical approaches for such determinations (9). Recall that agencies do not suggest which analytical approaches should be used for which measurement, and such choices are always left to the submitters to determine and justify. It remains the agencies’ main responsibility to determine if the sum total data provided by the abbreviated new drug application (ANDA [FDA]) or marketing authorization application (MAA [EMEA]) for a biosimilar justifies equating it with the chemical, biological, and medicinal properties and benefits of the innovator biopharmaceutical.
Agencies repeatedly indicate that first and foremost they are looking for analytical data that demonstrate true chemical equivalency as much as possible to the innovator drug, so human clinical studies are not required.


What Specific Analytical Data Should Be Generated to Support Submittals?
Proteins are characterized in numerous ways, and because they have primary, secondary, tertiary, and often, quaternary structures (higher order structures) in their native form, the possible approaches for their complete characterization are numerous. Full characterization of their total structures, primary and higher order, is required together with a viable demonstration of biological activity toward a particular substrate or substrates. That full characterization does not necessarily mean animal or human clinical studies.
Many references address the topic of characterization for the various aspects of protein structure (10–14). Besides the sequence of amino acids, which should be identical to that of the respective reference product for a biosimilar, there are numerous other physical and chemical properties that must also be accounted for and compared before biosimilarity can be judged.
In a reference presentation (15), the FDA presented a slide entitled “Analytical Tools to Evaluate Proteins,” shown here as a sidebar. Although it is not an exhaustive list of analytical approaches, we are going to use it to further discuss the specific analytical approaches that we recommend. We would like to emphasize that agencies look for complementary methods for analytical characterization and comparability of biopharmaceuticals. Using only ultrahigh-pressure liquid chromatography (UHPLC) or high performance liquid chromatography (HPLC) to compare the biosimilar to the reference product is usually insufficient to demonstrate chemical and structural equivalency. For decades, the biopharmaceutical industry has used orthogonal analytical tools such as high performance capillary electrophoresis (HPCE) modes to complement UHPLC data. The sidebar summarizes a recent FDA presentation of analytical tools to evaluate proteins with suggested approaches (15). This information has been further elaborated below.
To start, all proteins and their derivatives are based on specific sequences of amino acids. In general, complete digestion of the protein to individual amino acids is followed by some form of tagging, often with commercial reagents having enhanced ultraviolet (UV), fluorescence, mass spectrometry (MS), or other detection capabilities. Digestion is then followed by a separation-detection scheme, which can be UHPLC or HPCE. This step only provides a direct comparison of the amino acid composition of each biosimilar or biopharmaceutical, as well as relative or absolute amounts, using appropriately tagged amino acid standards for external quantitation and calibration. Such an approach can also indicate aberrant or unnatural amino acids in one or both species and the approximate levels or amounts, which can be very important especially if the reference product is known to have novel amino acids somewhere in the protein’s backbone. This approach does not indicate anything about sequences or absolute molecular weights, but it is usually a very good starting point for these comparisons. It should be pointed out that there are pressurized vessels and associated hardware that can increase the speed and efficiency of the protein’s digestion as well as tagging steps (16). The determination of amino acid composition by the above methods has become an accepted and expected analytical method in comparing a biosimilar with its innovator predecessor.
Protein sequencing is virtually always done using MS, in one form or another. There are many varieties, types, sizes, maximum resolutions, and various resolving parts or sectors (triple-quadrupole, time-of-flight, orbital ion trap, linear trap, orthogonal trap, ion cyclotron resonance, and other MS systems are available). There are many applications that involve a direct comparison of reference products (innovator–proprietary) to biosimilars. Any submission must clearly explain the techniques used, why they were selected, and how they are used to demonstrate biosimilarity. Protein sequencing and identification of all amino acids, as well as their variants (phosphorylated, glycosylated, deamidated, oxidized, reduced, disulfides, and so on), is generally performed using one of three basic approaches involving either ultrahigh-pressure liquid chromatography–electrospray ionization mass spectrometry (UHPLC–ESI-MS) or high performance capillary electrophoresis–electrospray ionization mass spectrometry (HPCE–ESI-MS) (17). These methods use top-down sequencing, middle-down sequencing, or bottom-up sequencing, but none of them are guaranteed to provide total sequencing and amino acid accounting. Even bottom-up sequencing does not always identify every single amino acid or its variants present. If the approach does not provide 100% sequencing, it also relies on databases to confirm the protein’s structure, which can be mistaken depending on how much of the protein has not actually been identified. In an ideal instance, the identical sequences (and levels of PTMs) should be derived for both the reference and biosimilar protein. If this is not the case, then the biosimilar submittal should explain the magnitude of any primary sequence differences, in quantitative terms, and the biological implications, if any.
Depending on the size and molecular weight of the protein, it may be necessary to perform subunit analysis using a variety of enzymes that cleave the protein at specific sites, which results in subunits-such as Fab, Fc, Fd, or others-that are easier to then fully sequence. Companies like Genovis offer such enzymes especially for characterizing monoclonal antibodies (mAbs) (18). Peptide mapping and bottom-up sequencing should also provide a comparison of the glycosylation patterns for each protein, both qualitatively and quantitatively. This comparison can, and usually is, performed in several ways, using peptide mapping alone to identify the location and identification of each glycosylation site, or by releasing all (or only N-termini) glycans to derive an UHPLC or HPCE–fluorescence–MS profile and characterization (percent levels of each glycan) between the innovator and biosimilar products.
Glycosylation
Glycosylation has long being considered a CQA for all glycoproteins, and it is known to vary as a function of how the protein was expressed, which expression system was used, what nutrients and chemicals were present, and how the glycoprotein was processed and purified (19). When comparing biosimilars with the reference products, the most glaring differences are often found when comparing glycosylation patterns on the intact protein or after removal as stand-alone glycans. There are at least three approaches taken to compare glycosylation patterns on the intact protein on subunits or peptide maps, and finally, on the total, released glycans after tagging with a variety of UV-, fluorescence-, and MS-sensitive tags. All of these approaches use some form of separations, generally UHPLC with UV, fluorescence, or MS detection modes, often using hydrophilic-interaction chromatography (HILIC) separations to resolve all of the free glycans or glycopeptides from other sample components before identification and relative or absolute quantitation by MS. All relevant analytical methods and their validations must be fully demonstrated in any filings of such data as well as the quantitative data and its statistical treatments.
Whatever the approach used to make these glycan comparisons, there will inevitably be differences found. Often, certain glycans found in the reference product will not appear in the biosimilar or vice versa, or the quantitations will not agree when the glycans are found in both places. These differences are perhaps inevitable given that the expression, harvest, and purification leading to the final drug product are likely to be different between the innovator and biosimilar products. There is no indication in any regulatory guidance as to how much of a difference becomes significant, or at what point the agency will deny the application because of such differences. The regulatory decision is likely to depend on the impact of the differences in glycosylation, especially whether those differences affect the safety or efficacy of the molecule in the particular clinical indication, and it will be important for any applicant to explain these potential impacts and demonstrate the lack of significance to safety or efficacy. It is unlikely that such glycan differences alone will be sufficient for nonapproval, and the applicant needs to provide the cumulative evidence indicating the biosimilar is of the same general structure, of high purity, well characterized with no adverse safety issues, effective, and patient-friendly. Again, the agency’s decision about approval will be done on a case-by-case basis.
Sequencing and Higher Order Structure
Sequencing (primary structure) is not a trivial step, because it can indicate novel or aberrant amino acids in the protein, the amount of oxidation of methionine or related amino acids, the number of disulfide bonds present and their locations, as well as the amount of deamidation of arginine or glutamine and location, amount of glycation and sites, loss of N- or C-terminal amino acids, and the location of glycans, types of glycans, or phosphorylated sites, and even, pegylation sites and amounts. In the case of antibody–drug conjugates, sequencing can provide the specific sites of drug adduction. When each peptide is fully sequenced, this type of information becomes available, in addition to the amino acid sequence. The beauty of current methods involving HPLC–ESI-MS or HPCE–ESI-MS for peptide mapping using one or more enzymes is that they are capable of providing a lot of this vital information about the primary-but only primary-structure and structural differences. At present, there are no alternative analytical methods capable of deriving such valuable, comparative information.
The higher order structure always involves some degree of folding of the primary structure, and its analysis focuses on the conformational analysis of the intact protein. This structure is crucial for biological activity and must be as identical as possible between the reference and biosimilar products. Unfortunately, other than X-ray diffraction (XRD) or nuclear magnetic resonance (NMR) analysis, none of the other methods available really provide a three-dimensional (3D) picture of a protein’s conformation in solution. XRD and NMR rely on analysis in a dry state (XRD) or in a solution (NMR) using solvents that are totally different than what are used in the final formulation, parenteral, or in vivo. Folding (see the sidebar) or conformations of the protein, to be more correct, can be ascertained in several other ways, some more specific than others but the most general analytical approaches have involved use of circular dichroism (CD), native fluorescence, Fourier transform infrared (FT-IR) spectroscopy, Raman spectroscopy, ion mobility spectrometry (IMS) (collisional cross section [CCS]), multiple angle light scattering (radius of gyration [Rg] or hydrodynamic radius [Rh]), and finally, hydrogen–deuterium exchange (HDX). Of these, some of these methods provide more definitive information about higher order structure than others, but none really provide complete information about the specific conformation present.
HDX is the new method on the block but it too does not really provide true conformations, though it can usually show differences in conformations between a proprietary and biosimilar product. Only recently, the FDA has begun to receive filings for both proprietary and biosimilar submittals, containing HDX results, so as to demonstrate conformations and their changes versus changes in temperature, solvents, formulations, and so forth. Since conformational changes can change the efficacy of any biopharmaceutical, it behooves the biosimilar submittal to make this comparison, as carefully as possible. Vast differences in conformations between the two products might well suggest differences in efficacy or safety. Rapid and simple environmental changes (sunlight, temperature, solvents, time) that lead to changes in conformation also affect protein stability, shelf life, long-term usage, and so forth. If the higher order structures for both proprietary and biosimilar products are identical, then their HDX patterns should be as close to one another as possible. If the HDX patterns are different, differences in the higher order structure and conformations may well be present.
Protein Complexes
Some biopharma products exist as protein complexes, and their efficacy depends on the stability of such complexes as well as the complex’s nature (number of subunits, types of subunits, and so forth). These subunits can often be easily assayed using chromatographic or electrophoretic methods, especially UHPLC or HPCE, together with MS or UV detection. Size-exclusion chromatography (SEC) often is used. Native MS has become very common today, and has proven very useful in demonstrating the nature of the subunits, their ratios, and even the precise nature and structure of each such subunit. IMS can provide quite accurate and reproducible CCS numbers, and these should be very close to one another for the reference and biosimilar proteins, if the proteins have very similar conformations. The goal in using IMS is to demonstrate that the numerous molecular ions generated from both the biosimilar and reference products are identical, and that when comparing the same charge states between the two, they will have the same CCSs for several, different charge states. However, IMS will not, by itself, specifically identify any of the subunits (even via CCS). It is solely a resolving chamber before the MS system itself, where the real work of identification almost always is performed. MS alone, or even with IMS and native MS, cannot provide true protein conformations.
Heterogeneity of size and molecular weights between the two proteins is most easily discerned using low-angle laser light scattering (LS) in one or more of its formats (static, dynamic, triple angle, multiangle, right angle, and so forth) or viscometry. Such methods have become de rigeur for demonstrating the presence or absence of protein complexes, as well as unwanted aggregates of the monomeric species. This approach provides either Rg or Rh (or both) for each protein, instrumentation dependent, and these numbers should be close to one another if the appropriate instrumentation is used. Commercial instrument suppliers include Agilent, Wyatt Technology, Malvern Technology, and PSS. Viscometry has been available as an online detection technique in liquid chromatography (LC) of proteins and peptides for several decades, but it is used less often than the LS variants mentioned above. Nevertheless, viscometry can be quite useful, especially in determining Rh in a much simpler, and more straightforward manner than most LS techniques.
Field-flow fractionation (FFF) or SEC, together with light scattering, does not always give reliable or accurate Rg or Rh values for the monomeric protein. Stand-alone (also known as batch mode) LS, without any initial separations involved, often provides better (more accurate and reproducible) numbers than when it is interfaced with SEC or FFF (20,21). However, batch analyses do not provide percent compositions of aggregates directly, which are easily obtained using SEC–LS methods. This data can be obtained knowing the correlation between the protein size or Rh and its molecular weight, and with suitable software and standards, thereby producing the percent aggregate profiles. Batch analyses can avoid complications when comparing aggregates between innovator and biosimilar. Dilution in SEC or FFF shifts the original equilibria, and interaction with silica supports can remove high-molecular-weight aggregates.
IMS can provide quite accurate and reproducible CCS numbers, and these should be very close to one another for the reference and biosimilar proteins if they have very similar conformations. The goal in using IMS is to demonstrate that the numerous molecular ions generated from both the biosimilar and reference products are identical. When comparing the same charge states between the two, they will have the same CCSs for several charge states. Those data may not be readily available yet from the literature comparing biosimilars with reference product proteins.
Bioactivity
Bioactivity refers to whether or not a biosimilar protein behaves in a biological system analogous to its reference product, and without this agreement, it is highly unlikely that it would have the same efficacy. Thus, bioactivity is used more to demonstrate that the biosimilar is biologically active against certain targets to the same degree and extent as the reference product. Bioactivity can be evaluated using immunoassays against specific antibodies for the target protein and to determine binding efficiency and effectiveness on and off rates, for the same target antibodies. Or, against known targets for the disease being treated, which is probably much more relevant to suggest. Immunoassays can determine equivalent reactivity and effectiveness in treating the disease. As shown in the sidebar, the FDA suggests using certain standard bioassay approaches, such as cellular and animal bioassays, ligand and receptor binding, or signal transduction. Positive responses should be compared with the reference product. Using cellular and animal bioassays, especially against target antibodies or receptor sites, are positives, suggesting a lack of need for human studies. Perhaps the two most prevalent analytical approaches involve enzyme-linked immunosorbent assays (ELISA) and surface plasmon resonance (SPR). Each of these approaches demonstrate binding to specific targets by the candidate protein, as well as on and off rates of such binding, so that numerical data are obtained for comparison purposes, which is often very telling and useful information. Equivalent binding to known targets or antigens for a mAb, between the innovator and biosimilar, is encouraging but only means there is comparable binding. It does not necessarily mean equivalent efficacy under actual clinical conditions with diseased patients.
However, there are other, newer approaches that are termed affinity HPLC or affinity CE. Both of these techniques rely upon an initial, external binding of the protein to a receptor or target site or protein, and their separation from unbound protein by the HPLC or CE conditions. The biosimilar protein can be introduced into a column with an immobilized target (HPLC) or introduced as a solution in both HPLC or CE. As the pairing of the target with the protein of interest occurs throughout the separation process, the degree of retardation of bound versus free ligand–protein becomes apparent as a change in retention or migration times. The stronger the binding during the separation, the greater the retardation or difference in migration tendencies between the free and bound protein of interest. Often, individual chromatographic or electrophoretic peaks can appear for the protein target–receptor bound pair, which will have different migration or elution times from the unbound protein. The ratio of these two peaks can then indicate the degree or strength of binding for the candidate biosimilar protein toward that particular target-receptor. All of these affinity-separation techniques have been well described in the literature, but that is not the case for comparing biosimilars to reference protein products. However, equivalent on and off rates or binding to any target does not guarantee efficacy under actual clinical conditions, as stated above.
Aggregation
Aggregation refers to the usually unwanted occurrence of higher order species of the monomeric protein, and it is often problematic with protein products. It is a function of the specific protein, temperature, concentration, and molecular weight. It is a dynamic, equilibrium process and a function of the concentration of the protein, the nature of the solution medium, temperature, and molecular weight. It is considered to be a deleterious side effect of the formulation and should be prevented as much as possible. Aggregates are also believed to be immunogenic to the patient and are often difficult to remove from the final formulation. It must be demonstrated that they are either absent or present at below certain percent levels, and that they are not harmful or immunogenic to the patient’s condition. They are not covalent dimers, trimers, or higher order species of the monomeric protein, but rather they are in constant equilibrium with the monomer, as a function of concentration, temperature, molecular weights, and solution medium. If the initial mixture of aggregates is physically removed from the monomer, once the monomer is in the same solution again, it will just reform the same aggregates, usually to the same percent compositions. The higher the monomer protein’s concentration and molecular weight, usually the greater the amount and types of aggregates that are formed.
There are several different analytical techniques in current use to demonstrate the presence and percent compositions of aggregates, but because there are usually no real standards for the aggregates, absolute percentages present are impossible to demonstrate. The most common analytical approaches in use today to demonstrate aggregates involve analytical ultracentrifugation (AUC), SEC, multiple-angle laser light scattering (MALS), right-angle light scattering (RALS), low-angle laser light scattering (LALLS), and SEC–MALS or FFF, which often is also combined with LS (FFF-LS). AUC is not able to be interfaced with any initial separations step, so it is always run as a stand-alone technique, often with tremendous success, although it is not always foolproof for very low molecular weight peptides. SEC alone and FFF alone only separate, ideally, the species present but provide no actual information about their molecular weights unless the techniques are interfaced with some form of LS or viscometry. SEC has appeared to be much more useful and successful with the vast majority of protein drugs, rather than FFF, which seems much better for subvisible or visible particle characterizations than for typical protein aggregates (22). There are some potentially serious deficiencies in using SEC methods-they can adsorb aggregates and not release them together, and they dilute the injected solution so that a change in the ratio of aggregates to monomer may readily occur, negating the entire approach (change in sample during analysis). The ratio of monomer to aggregates for most proteins is often dependent on concentration of the monomer, and as that changes, so too will the relative amount of aggregates observed (20,21).
Another technique involves chemical cross-linking of aggregates before performing SEC–MS or direct MS. In this approach, the mixture of monomer to aggregates is chemically cross-linked using various commercial reagents, so that noncovalent aggregates are fixed in time and space. It is assumed there is no additional formation of aggregates after cross-linking. But, when the covalent aggregates are introduced into the MS system, they do not fall apart, and they are measured at the same levels as in the injected sample. They can also be separated first by SEC–LS from the uncomplexed monomers, and the percent composition can be determined, as is done for noncrosslinked aggregates. This approach probably gives a better, well-defined indicator of the percent compositions of monomer, dimer, trimer, and so on than direct-injection MS. This area of chemical cross-linking and MS has become very useful for performing native MS analyses and for determining protein complexes that involve noncrosslinked proteins of different types. The crosslinking also does not change the nature of the monomer–dimer–trimer mixture because the original aggregates are still present in the solution. However, the equilibrium of monomer to aggregates has been changed, and it is unknown whether more noncrosslinked aggregates will be released with time.
Proteolysis
Proteolysis relates to how the protein of interest undergoes lysis or cleavage by other proteins-usually enzymes-or harsh chemical conditions (pH, temperature, solvents). Because proteolysis leads to smaller fragments of the parent protein, similar to enzymatic degradation by enzymes used for peptide mapping, the techniques to discern proteolysis are the same. The only difference is that the fragments formed by proteolysis are usually much larger than those formed from trypsin or endo-LysC or IdeS enzymes in peptide mapping or subunit formations. Thus, the techniques commonly used are reversed-phase, size-exclusion, or ion-exchange UHPLC–ESI-MS; HPCE–ESI-MS using capillary zone electrophoresis (CZE); and capillary gel electrophoresis (CGE) or isoelectric focusing (size dependent), but always with MS detection. Given that proteolysis usually results in more than a single, lower-molecular-weight fragment, direct MS analysis is usually not feasible because of ion suppression effects.
Impurities
Impurities are usually chemicals not relevant to the applications of the biosimilar protein, and they often arise accidentally. They are usually organic or inorganic low-molecular-weight species, though they can be host-cell proteins, protein A, or enzymes used to tailor the final protein from higher-molecular-weight starting materials. The International Conference on Harmonization’s (ICH) recent guideline ICH Q3D (23) is under implementation by agencies for assessment of elemental impurities in products, and it requires a risk assessment to be presented in any new submission. Often metals and inorganics can be removed by ion chromatography, by solid-phase extraction cartridges for organics–inorganics, by changing the solvent, by ultrafiltration, or by extraction with organic solvents that do not disrupt the bioactivity of the desired protein. The successful removal of impurities is determined using the same analytical methods that suggested their presence in the drug substance or product. Most often, that again involves some form of UHPLC–MS, inductively coupled plasma (ICP)–MS, or HPCE–MS.
Summary
As biosimilar development and production becomes even more global, regulations will continue to evolve and over time improved guidance on level-of-data similarity may be published. However, the onus is now and will always be on companies to provide agencies with a strong scientifically based data package using analytical data to support and justify biosimilarity for a particular molecule and clinical indication. Continued dialogue between companies and agencies should be encouraged to determine up front what studies and data are necessary to gain approval in a global marketplace.
References
- S.A. Berkowitz, J.R. Engen, J.R. Mazzeo, and G. B. Jones Nat. Rev. Drug Discovery11(7), 527–540 (2012).
- S. Kozlowski, J. Woodcock, K. Midthun, and R. Behrman Sherman, N. Engl. J. Med.365(15), 385–388 (2011).
- G. Eranitsaris, E. Amir, and K. Dorward, Current Opinion Drugs71(12), 1–10 (2011).
- H. Schellekens, Nat. Biotechnol.22(11), 1357–1359 (2004).
- http://www.gabionline.net/Guidelines, GaBI, Generics and Biosimilars Initiative, 1-29-16, Guidelines by FDA for biosimilars (submittals, meetings, discussions, etc.).
- (6) US Food and Drug Administration, Guidance for Industry: Scientific (Quality) Considerations for Demonstrating Biosimilarity to a Reference Products, (FDA, Silver Spring, Maryland, 2015) http://www.fda.gov/Drugs/GuidanceComplianceRegulatoryInformation/Guidances/default.htm.
- Update on Biosimilars US Regulation, 1st Quarter, 2016, Policy and Medicinehttp://www.policymed.com/2016/04/update-on-biosimilars-1st-quarter-2016.html.
- F. Greer, The Analytical Scientist44, 24–29 (2016).
- I.S. Krull, A. Rathore, and J.A. Loo, LCGC North Am. 34(7), 492–499 (2016).
- R.L. Lundblad, Approaches to the Conformational Analysis of Biopharmaceuticals (Chapman Hall/CRC, Taylor & Frances Group, Boca Raton, Florida), 2009.
- Characterization of Protein Therapeutics Using Mass Spectrometry, G. Chen, Ed. (Springer Science & Business Media, New York, 2013).
- Protein Biotechnology, Isolation, Characterization, and Stabilization, F. Franks, Ed. (Humana Press, Totowa, New Jersey, 1993).
- S. Podzimek, Light Scattering, Size Exclusion Chromatography and Asymmetric Flow, Field Flow Fractionation, Powerful Tools for the Characterization of Polymers, Proteins and Nanoparticles (John Wiley & Sons, Inc., Hoboken, New Jersey, 2011).
- Peptide Characterization and Application Protocols, G.B. Fields, Ed. (Humana Press, Totowa, New Jersey, 2007).
S.Kozlowski, “US FDA Perspectives on Biosimilar Biological Products,” presented at the 2014 Biotechnology Technology Summit, IBBR University of Maryland, Rockville, Maryland, 2014,
https://www.ibbr.umd.edu/sites/default/files/public_page/Kozlowski%20-%20Biomanufacturing%20Summit.pdf- Pressure Biosciences, Inc., South Easton, Massachusetts, www.pressurebiosciences.com/.
- Genovis, Enzymes for Antibodies (Genovis AB, Lund, Sweden), www.genovis.com/.
- J. Batra and A.S. Rathore, Biotech. Progress DOI 10.1002/btpr.2366 (2016).
- I.S. Krull and A.S. Rathore, LCGC North Am.33(1), 43–48 (2015).
- S.A. Berkowitz, I.S. Krull, and A.S. Rathore, LCGC North Am.33(7), 478–489 (2015).
- A. Singla, R. Bansai, V. Joshi, and A.S. Rathore, AAPS J.18, 689–702 (2016).
- International Conference on Harmonization, ICH Q3D Elemental Impurities, Guidance for Industry, (ICH, Geneva, Switzerland, 2015).


Diane Wilkinson is a PhD graduate in pharmaceutical sciences from Manchester University, UK and a pharmacy graduate from Nottingham University, UK. Diane has worked for more than 30 years in various technical development and regulatory roles within the pharmaceutical and biotechnological industry and is now employed by Biogen, as a Global Regulatory CMC Director.
Ira S. Krull is a Professor Emeritus with the Department of Chemistry and Chemical


Biology at Northeastern University in Boston, Massachusetts, and a member of LCGC’s editorial advisory board.


Anurag S. Rathore is a professor in the Department of Chemical Engineering at the Indian Institute of Technology in Delhi, India.


















Common Challenges in Nitrosamine Analysis: An LCGC International Peer Exchange
April 15th 2025A recent roundtable discussion featuring Aloka Srinivasan of Raaha, Mayank Bhanti of the United States Pharmacopeia (USP), and Amber Burch of Purisys discussed the challenges surrounding nitrosamine analysis in pharmaceuticals.


Regulatory Deadlines and Supply Chain Challenges Take Center Stage in Nitrosamine Discussion
April 10th 2025During an LCGC International peer exchange, Aloka Srinivasan, Mayank Bhanti, and Amber Burch discussed the regulatory deadlines and supply chain challenges that come with nitrosamine analysis.


