“Signature” Analysis of Complex Environmental Samples Using Nontargeted Two‑Dimensional Gas Chromatography
Novel nontargeted analysis applications in two-dimensional gas chromatography–mass spectrometry (GC×GC–MS) and GC–high‑resolution (HR)MS have enabled the discovery of new contaminants. Now, the next frontier is nontargeted analysis for the elucidation of the mechanisms of (bio)chemical reactions in complex samples, such as the biodegradation of organics in water and soils or the conversion of plastics into oils. GC has the potential to contribute greatly to the optimization of these processes and therefore make a real contribution to net zero and circular economy agendas.
Nontargeted analysis (NTA) is fast becoming an important branch of chromatography and mass spectrometry (MS). It is a departure fron traditional analytical approaches where compounds of interest are specifically sought in samples. NTA takes a holistic view of the composition of complex samples; the whole “chemical space”, all of the chemicals present in a sample, are investigated. It has been enabled by new technologies, such as novel hardware developments, and a boom in data science. While biological applications have led the way, environmental sciences are also central to the rapid expansion of this technique.
Environmental applications have often pushed the boundaries of chromatography and mass spectrometry, and this will continue as their role in meeting the UN Sustainable Development Goals grows (1). In environmental sciences, NTA consists mostly of suspect and nontargeted screening (S&NTS). S&NTS is employed to look exhaustively at the data produced through an analytical system. Suspect screening is the discovery of known unknowns: micropollutants for which identification can be carried out by comparison with standards or by matching mass spectra to libraries. Nontargeted screening is the identification of unknown unknowns: newly discovered micropollutants for which putative identification can be attempted by structural analysis of a mass spectrum or using the accurate mass of their ions. The coupling of liquid chromatography (LC) with high resolution mass spectrometry (HRMS) initially elicited the rise of NTA and methodologies for S&NTS. Benchmarking and harmonization are now needed for these workflows, and community efforts such as the NORMAN Collaborative Non-target Screening Trial (2) and EPA’s Non‑Targeted Analysis Collaborative Trial (3) have begun instituting common standardized practices. In 2018, the Benchmarking and Publications for Non‑Targeted Analysis Working Group (BP4NTA) (4) was formed and includes scientists from across the world.
Turning to GC for Nontargeted Analysis
While LC–HRMS seems to be accepted as a “complex analytical strategy”, it appears that many users are still reluctant to embrace gas chromatography (GC) applications that produce complex data. GC coupled with MS via electronic ionization (EI), however, has been used for nontargeted work long before the concept of NTA was defined. EI permits compound annotation by both robust matching with library samples and structural analysis of mass spectra. Nowadays, two technological advances are keeping GC analysis relevant for NTA, GC–HRMS and comprehensive two‑dimensional gas chromatography (GC×GC). GC–HRMS provides the resolution that GC–MS might lack for NTA, while GC×GC provides access to the highest peak capacity of all chromatographic techniques. The exhaustive separation through two columns results in a high-resolution structured two-dimensional chromatogram, where related compounds elute in clustered bands across the chromatographic plane (Figure 1). This provides an additional advantage for compound annotation because it can be deduced based on related annotated compounds. While GC×GC needs to be coupled with fast scanning mass spectrometers and often with time of flight (TOF), it has also been successfully coupled with high-resolution mass spectrometers; GC×GC–HRMS is a tool with tremendous potential for NTA.


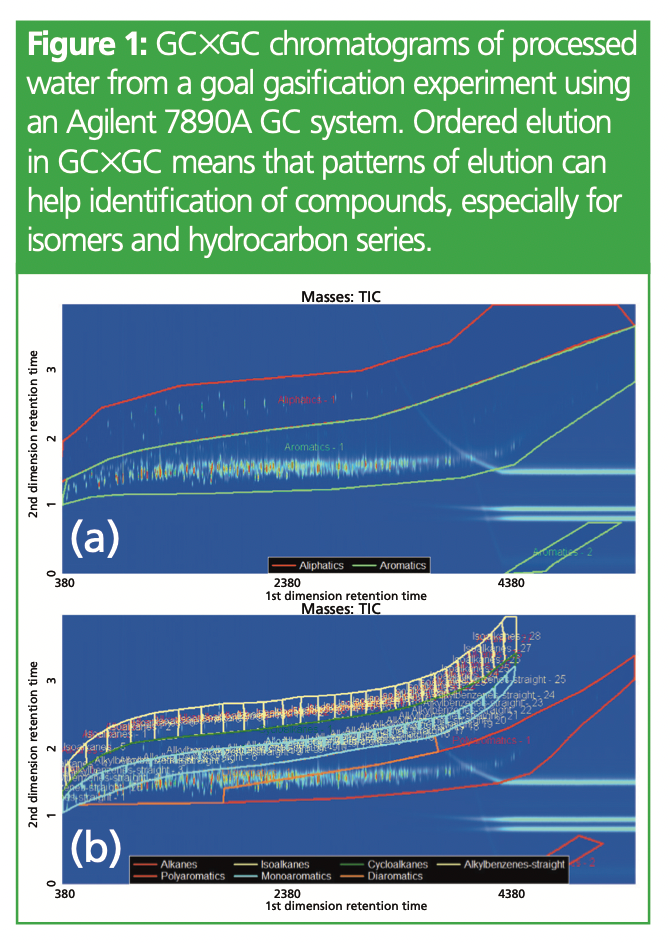
NTA with GC contributes to the net zero and circular economy agenda through applications in environmental engineering. These include public health, water, soil and air pollution, solid and water waste treatments, and any process intended to limit the damages of human activities on the environment. Since Jungclaus, Lopez-Avila, and Hites first used GC–EI-MS to identify previously unknown organic contaminants in the wastewater of a specialty chemical manufacturing plant in 1978 (5), micropollutants—from pharmaceuticals to per- and polyfluoroalkyl substances (PFAS) and including persistent organic contaminants—have been identified and tracked in wastewater, drinking water, sewage sludge, and irrigation waters. In recent years, GC×GC–HRMS has enabled exhaustive discovery of emerging semivolatile contaminants, such as nonpolar halogenated or polyhalogenated compounds, in media such as electronic waste dust or wastewater.
Potential of GC×GC Nontargeted Analysis for Environmental Engineering
NTA, however, has potential beyond S&NTS for applications in environmental engineering. Emerging approaches show that GC×GC data can be used to understand how an environmental system changes through physical and (bio)chemical transformations. When colleagues and I set out to forensically analyze samples from coal tar non-aqueous phase liquids from former gas work sites, our optimized GC×GC methods, using a time-of-flight mass spectrometer, connected to a gas chromatograph equipped with a thermal modulator, enabled us to separate several thousands of peaks (6) Multivariate analysis showed that, although the tar was highly weathered, 252 of those peaks could be used to associate a sample with the type of manufacturing process that had produced the coal tar (7); the identity of these 252 compounds being only relevant a posteriori as they could be related to the chemistry of the gas manufacturing process. Meanwhile, in a series of landmark papers, Reddy et al. demonstrated how the structured elution in GC×GC could be used to map out mass transfer of compounds in a marine oil spill sample and apportion quantitatively the various weathering processes (8–10). In later work, they showed that partial least squares‑discrimant analysis (PLS-DA) on whole GC×GC chromatograms facilitated the identification of precursors of oxidated compounds in aged spills—uncovering an unreported chemodynamic process in oil spill weathering (11). When our group looked at the relationship between contaminants and microbial ecology in coal tar contaminated soils, we used sparse PLS-DA to identify features that were representative of the correlation between the presence of certain classes of compounds, and certain types of bacteria—these could be considered “exemplars” or markers (12).
The amount of information contained in GC×GC chromatograms coupled with the right mathematical or statistical methods have the potential to elucidate the mechanisms of the transformation of complex environmental systems and to isolate markers for these reactions. GC×GC is already used for compositional characterization of complex samples taken from environmental engineering processes including remediation of hydrocarbon contamination, oil production by pyrolysis of plastic waste, and refinery effluent treatment. If it was used in these systems to reveal (bio)chemical mechanisms and their dependence on various parameters, real-time optimization and monitoring could be enabled.
Signature Analysis for Environmental Samples


The chemical load of environmental samples changes over time and with stressors—similar to handwriting and, in particular, the signature of an individual (Figure 2). For this reason, for environmental sample analysis, the term chemical signature rather than chemical fingerprint should be used. It follows that one simple way to understand the potential benefits of NTA as an approach in extracting novel information from samples—which targeted analysis cannot—is to define it as an analysis of signatures. Signature analysis aims to exploit fully the hardware capacity of GC×GC, and no assumption is made about which compounds will best answer the questions we have about a system. It requires a step change in most aspects of analysis compared to targeted analysis of complex samples (Figure 3).

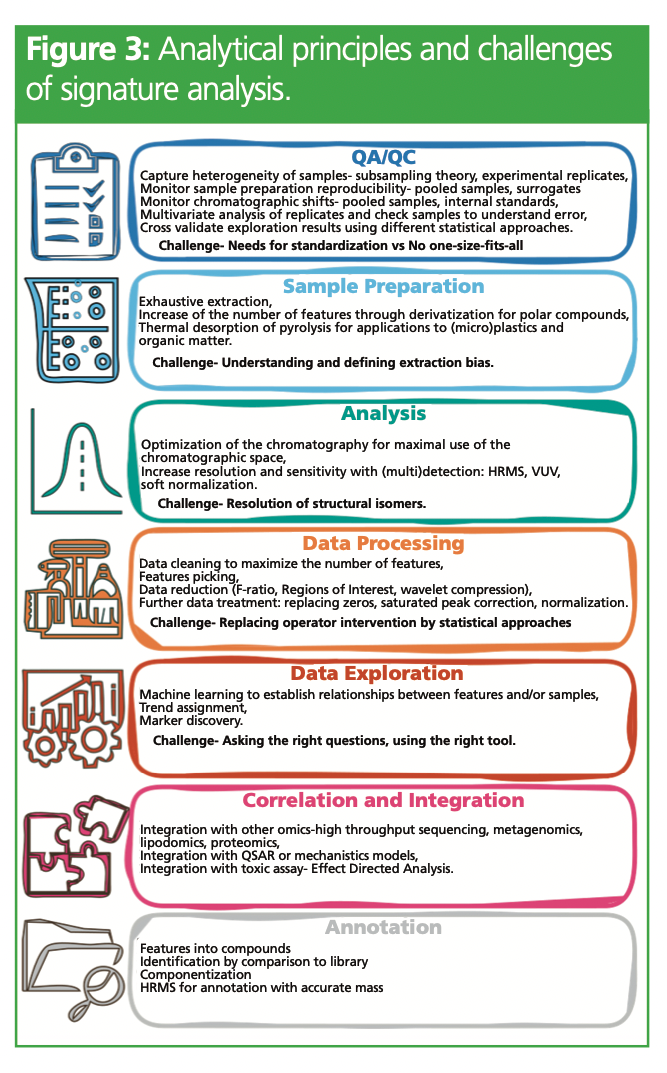
Sample preparation must be focused on exhaustiveness rather than specificity. This means using a broad range of solvents and phases or combining extraction fractions together. The reach of the extraction can also be increased to include more polar compounds, often important (bio)degradation products, by derivatization. Any exhaustive sample preparation, however, will have some inherent limitations—an “extraction bias”—that needs to be understood by the analysts. The analytical method must also be comprehensive and make maximal use of the chromatographic space by optimization of the column set. Resolution can be further augmented with the use of “orthogonal” detectors, specific detectors not based on mass spectrometry; vacuum ultraviolet (VUV) detectors, for instance, have successfully been coupled with GC×GC. Sensitivity and annotation can also be increased by using HRMS or soft ionization. The chromatogram must then be divided into “features”; these can be peaks, but for GC×GC NTA applications they are more likely to be “bins” or “tiles”, a subsection of the chromatogram not necessarily directly matched to an individual compound. Annotating all the features in a complex GC×GC chromatogram might be tempting but is not efficient in signature analysis. Instead, data reduction must be carried out to only take forward the features or regions that show big variations within samples sets. Once the feature table is ready, machine learning can be employed to determine relationships between them. Metabolomics data pipelines are mostly based on the comparison of different “groups” (healthy vs. diseased), while pipelines for environmental S&NTS are aimed at prioritization based on intensity and/or chemical properties. Neither are appropriate for signature analysis, and novel statistical workflows for identification of trends in time or spatial series are needed. Each feature in the feature table should be matched to a trend and exemplars identified for each trend. Negative or positive correlations between trends can also be investigated. Success will depend on selecting the correct statistical tools based on well-defined research questions. For further mechanism elucidation, correlation analysis with other biological nontargeted analysis such as metagenomics can reveal associations with biological functions, or the data can be integrated with mathematical modelling such as quantitative structure-activity relationship (QSAR) or mechanistic models. Identification and annotation of features of relevance does not need to happen until this stage in the process. It can be done by conventional approaches using libraries and standard comparison, or, if needed, HRMS can be used.
Through binning or tiling, features are not necessarily single compound, so further clean-up of the data might need to happen to cluster features that are the same compound, or separate compounds that appear in the same feature. Homologous series and compounds with similar mass spectra can also be grouped together. These processes are sometimes referred to as componentization.
Reimagining QA/QC Procedures to Incorporate NTA
The departure from targeted analysis signifies that quality assurance/quality control (QA/QC) procedures need to be reimagined. Crucially, they need to demonstrate that the sample preparation is reproducible across the chemical space, so that samples can be compared to each other. They need to monitor chromatographic shifts along the whole chromatogram, in both dimensions. Enough samples should be analyzed, or enough information should be available on reproducibility, to provide the statistical power necessary for data exploration. Multivariate analysis should be applied to check samples (of pooled samples, for instance) and experimental and technical replicates to investigate experimental and processing error and batch effects. To reduce type 1, when a feature is incorrectly identified as an individual compound, and type 2, when a compound of significance is not picked up by the workflow for errors in data exploration, several machine learning methods should be used to test the hypothesis.
Signature analysis with GC×GC–MS has tremendous potential for accelerating the optimization of engineering processes involving complex samples and is thus particularly suited to environmental engineering applications. Coupling with HRMS and VUV promises to further unlock this potential. Rapid development in pyrolysis and thermal desorption as sample preparation for GC extends the field to the analysis of compounds such as organic matter and (micro)plastics.
Conclusion
The possible applications in environmental engineering are broad: wastewater treatment, contaminated land, marine pollution, drinking water treatment. Our group is currently developing very novel methods to characterize the organics adsorbed onto the surface of activated carbon from biofilters; thermal desorption coupled with GC×GC–MS is enabling us to understand better the mechanisms of drinking water treatment (13). In a field where GC is usually used by non-specialists as a “black box” for targeted analysis, the complexity of the approach remains a major limitation for the democratization of the method. In recent years, vendors have worked closely with environmental analytical chemists to develop both hardware and software solutions for S&NTS.
Collaboration must continue between environmental engineers, analytical chemists, and vendors to develop robust workflows along the adjacent fields of metabolomics and S&NTS, and to pursue the effort of standardization by participating in BP4NTA and specialist meetings such as GC meets NTS (14).
References
- UN Sustainable Development Goals: https://sdgs.un.org/goals
- Norman Network. https://www.norman-network.net
- Ulrich, E. M.; Sobus, J. R.; Grulke, C. M.; et al. EPA’s Non-targeted Analysis Collaborative Trial (ENTACT): Genesis, Design, and Initial Findings. Analytical and Bioanalytical Chemistry 2019, 411, 853–866. DOI: 10.1007/s00216-018-1435-6
- BP4NTA. https://nontargetedanalysis.org
- Jungclaus, G.; Avila, V.; Hites, R. Organic Compounds in an Industrial Wastewater: A Case Study of their Environmental Impact. Environ. Sci. Technol. 1978, 12, 88–96. DOI: 10.1021/es60137a015
- McGregor, L. A.; Gauchotte-Lindsay, C.; Nic Daéid, N.; et al. Ultra Resolution Chemical Fingerprinting of Dense Non-Aqueous Phase Liquids from Manufactured Gas Plants by Reversed Phase Comprehensive Two-Dimensional Gas Chromatography. J. Chromatogr. A 2011, 1218, 4755–4763. DOI: 10.1016/j.chroma.2011.05.045
- McGregor, L. A.; Gauchotte-Lindsay, C.; Nic Daéid, N.; Thomas, R.; Kalin, R. M. Multivariate Statistical Methods for the Environmental Forensic Classification of Coal Tars from Former Manufactured Gas Plants. Environ. Sci. Technol.2012, 46, 3744–3752. DOI: 10.1021/es203708w
- Arey, J. S.; Nelson, R. K.; Xu, L.; Reddy, C. M. Using Comprehensive Two-Dimensional Gas Chromatography Retention Indices To Estimate Environmental Partitioning Properties for a Complete Set of Diesel Fuel Hydrocarbons. Anal. Chem. 2005, 77, 7172–7182. DOI: 10.1021/ac051051n
- Arey, J. S.; Nelson, R. K.; Reddy, C. M. Disentangling Oil Weathering Using GC×GC. 1. Chromatogram Analysis. Environ. Sci. Technol. 2007, 41, 5738–5746. DOI: 10.1021/es070005x
- Arey, J. S.; Nelson, R. K.; Plata, D. L.; Reddy, C. M. Disentangling Oil Weathering Using GC×GC. 2. Mass Transfer Calculations. Environ. Sci. Technol. 2007, 41, 5747–5755. DOI: 10.1021/es070006p
- Aeppli, C.; Carmichael, C. A.; Nelson, R. K.; et al. Oil Weathering After the Deepwater Horizon Disaster Led to the Formation of Oxygenated Residues. Environ. Sci. Technol. 2012, 46, 8799–807. DOI: 10.1021/es3015138
- Gauchotte-Lindsay, C.; Aspray, T. J.; Knapp, M.; Ijaz, U. Z. Systems Biology Approach to Elucidation of Contaminant Biodegradation in Complex Samples – Integration of High-Resolution Analytical and Molecular Tools. Faraday Discuss. 2019, 218, 481–504. DOI: 10.1039/c9fd00020h
- 14th Multidimensional Chromatography Workshop: http://www.multidimensionalchromatography.com/uploads/5/8/9/1/58913545/_14mdcw_final_program.pdf
- GC Meets NTS: https://afin-ts.de/gc-meets-nts-2022/?lang=en
Caroline Gauchotte-Lindsay is a senior lecturer in water and environmental engineering at the University of Glasgow. She is an analytical chemist embedded in an engineering department and develops new chromatographic and spectroscopic tools and sensors to support more performant environmental (bio)technologies, such as contaminated land remediation, drinking water treatment, and wastewater treatmen



















University of Rouen-Normandy Scientists Explore Eco-Friendly Sampling Approach for GC-HRMS
April 17th 2025Root exudates—substances secreted by living plant roots—are challenging to sample, as they are typically extracted using artificial devices and can vary widely in both quantity and composition across plant species.

Sorbonne Researchers Develop Miniaturized GC Detector for VOC Analysis
April 16th 2025A team of scientists from the Paris university developed and optimized MAVERIC, a miniaturized and autonomous gas chromatography (GC) system coupled to a nano-gravimetric detector (NGD) based on a NEMS (nano-electromechanical-system) resonator.

Miniaturized GC–MS Method for BVOC Analysis of Spanish Trees
April 16th 2025University of Valladolid scientists used a miniaturized method for analyzing biogenic volatile organic compounds (BVOCs) emitted by tree species, using headspace solid-phase microextraction coupled with gas chromatography and quadrupole time-of-flight mass spectrometry (HS-SPME-GC–QTOF-MS) has been developed.


