Identifying "Known Unknowns" in Commercial Products by Mass Spectrometry
LCGC Europe
A systematic approach for the identification of nontargeted species using nominal and accurate mass data searching both mass spectral and "spectral-less" databases is described.
The identification of nontargeted species in environmental and commercial samples by mass spectrometry can be very difficult. In this column instalment, guest authors from Eastman Chemical Company describe their systematic approach for the identification of nontargeted species using nominal and accurate mass data, searching both mass spectral and "spectra-less" databases.
Organic mass spectrometry (MS) has witnessed an extraordinary increase in capabilities this past decade because of major advances in ionization sources, analysers, detectors, chromatography and computer technology. Many of these technological advances focus on biological applications, a fact plainly evident to attendees of the American Society for Mass Spectrometry's (ASMS) annual conferences. Yet the significance of this ever-sophisticated technology has not been lost on industrial, environmental and forensic mass spectrometrists, whose work involves characterizing commercial chemical products.
Eastman Chemical Company is a global manufacturer of polymers, fibres, coatings, additives, solvents, adhesives and many other products. Gas chromatography–mass spectrometry (GC–MS) and liquid chromatography–mass spectrometry (LC–MS) have proven to be essential for characterizing our company's products and those of other companies. With reasonable effort, we routinely and reliably obtain mass spectral data from these highly sensitive, yet robust techniques. However, unless the data can be converted into structural information, it is not useful as a knowledge base to resolve the analytical problem at hand.


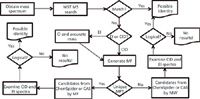
Figure 1: Simplified flowchart for identifying "known unknowns." MF = molecular formula and MW = molecular weight.
In the last 34 years, we developed and refined a systematic process (1,2) for the identification of nontargeted species using GC–MS and LC–MS analyses. We refer to these types of species as "known unknowns" — that is, species known in the chemical literature or MS reference databases, but unknown to the investigator. The essence of the process is finding candidate structures by searching mass spectral databases, Chemical Abstract Services databases and ChemSpider databases. Figure 1 presents a simplified flowchart of the overall process; the subsequent sections discuss individual steps and illustrate three examples in the identification of known unknowns.
Computer-Searchable Mass Spectral Databases
The first step in the process is computer searching of spectra against mass spectral databases. This approach (3) is very powerful and efficient for the identification of unknowns typically requiring 3–5 s for each component in a mixture. Electron ionization (EI) databases are used for identifying compounds in GC–MS analyses, and collision-induced dissociation (CID) databases are used for LC–MS analyses. The databases are purchased from commercial sources or are created from compounds characterized at our company (see Table 1).


Table 1: Spectra with associated structures searched with NIST search software.
The results of the EI mass spectral searches are normally more successful than CID searches for two reasons. First, the number of entries in EI databases for GC–MS is approximately 10 times larger than that for CID databases for LC–MS. Second, 70-eV EI spectra are much more reproducible than CID spectra, which can vary significantly depending on instrument design and user-specified variables (3).
NIST MS Search Software as Eastman Corporate Standard
We adopted the National Institute of Standards and Technology (NIST) MS Search program as our corporate standard for searching mass spectral databases for the following reasons:
- Searches both EI and CID databases
- Performs fast EI searches with essentially no false negatives (3)
- Searches libraries by spectra, structure and other data fields
- Merges search results for multiple databases
- Creates users' libraries with structures and other data fields
- Merges, archives and distributes users' libraries nightly
- Imports spectra and structures from all major commercial software programs
- Correlates fragments to substructures for EI and CID spectra via MS Interpreter utility
The automated process of merging, archiving and distributing our corporate EI and CID databases occurs nightly by means of batch files and a simple event-scheduler utility. A standard GC–MS laboratory computer on the network serves as the sole library server for our company, which operates a worldwide computer network of MS systems. Many of these remote systems are operated by scientists with minimal expertise in mass spectral interpretation. When necessary, those scientists send their files via the network for interpretation by corporate experts in MS. The experts then add spectra and associated structures to our corporate database.
Soft Ionization for Molecular Weight Determinations
The molecular weight of a component is one of the most important pieces of information obtained from MS analysis. CID spectra obtained by LC–MS analyses that use "soft" ionization techniques, such as electrospray ionization (ESI) and atmospheric pressure chemical ionization (APCI), normally yield ion species that indicate the molecular weights of components. In contrast, the molecular ions of components often go unobserved in EI analyses. We use chemical ionization (CI) to determine the molecular weights of those components in EI GC–MS analyses.
We use a wide variety of CI gases and gaseous mixtures in GC–MS analyses including methane, isobutane, ammonia, ammonia-d3 (4), methylamine and others. The choice of gas depends on the proton affinity of the unknown. We primarily use ammonia, however, because most of our unknowns contain heteroatoms. Ammonia CI yields very good molecular weight information (proton adducts, ammonium adducts or both). Moreover, it does not leave carbon deposits that contaminate and ultimately hinder the performance of the CI source. MS CI manifolds supplied by the manufacturers for many of our GC–MS instruments are incompatible with ammonia gas, so we fit our instruments with custom manifolds (4). In addition to tolerating ammonia, the custom manifolds provide easy in situ preparation of gaseous mixtures.
Accurate Mass Data for Molecular Formula Determinations
The wide availability of time-of-flight (TOF), quadrupole TOF (Q-TOF) and orbital trap mass analysers allow the routine acquisition of high resolution mass spectral data with low partspermillion (ppm) mass accuracy in either LC–MS or GC–MS modes. In many cases (5), even a mass accuracy of <1 ppm is inadequate to determine a unique molecular formula (MF). Therefore, mass spectrometry vendors apply orthogonal filters such as isotopic ratio abundances and a variety of heuristic and chemistry rules (6) to limit the number of molecular formulas.
Searching "Spectra-Less" Databases
The limited number of spectra in commercial databases as well as our corporate mass spectral databases dictates the use of other databases for the identification of known unknowns. For many years, we have used "spectraless" databases (7,8) such as our internal plant material database and the Toxic Substances Control Act (TSCA) listing for identifications. These databases contain no computer searchable mass spectra and are searched only by monoisotopic mass, average molecular weight or molecular formula. Unfortunately, data evaluation proved tedious because no orthogonal filters were available to prioritize the candidate lists, and these databases did not offer structures.
Recently, we have found the Chemical Abstracts Service (CAS) Registry (>70 million substances) and ChemSpider (>28 million entries) are particularly valuable spectraless databases for identifying known unknowns (1,2). Both databases are accessed via intuitive web-based interfaces. The CAS Registry is a fee-based system and ChemSpider is provided as a free resource to the community. Both are searched by molecular formula and the results are sorted by the number of associated references. The correct structure routinely appears among the top 1–5 hits in the sorted lists for a variety of classes of compounds.
The highly curated CAS Registry includes many key words associated with substances. For relatively obscure substances (that is, those with fewer associated references), it is often very useful to query the list of candidate compounds by key words determined from minimal sample history (1). This approach is not available within ChemSpider.
Searching Spectra-Less Databases by Molecular Formula Versus Molecular Weight
The molecular formula is without doubt the best search parameter for querying spectra-less databases for candidate structures. However, we demonstrated (1,2) that searching by molecular weights can be particularly useful when unique molecular formulas cannot be determined for higher molecular weight (>600 Da) compounds. In theory, as the molecular weight of an unknown increases, the number of possible molecular formulas increases dramatically. Yet in practice, the number of compounds observed in both the CAS Registry (Figure 2) and ChemSpider databases decreases dramatically as a function of increasing molecular weight.

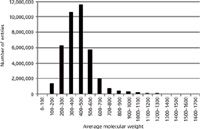
Figure 2: Number of CAS registry substances versus average molecular weight.
You can search the ChemSpider database by a monoisotopic mass using a mass range consistent with the accuracy of the user's measurement. In contrast, you can only search the CAS Registry with SciFinder by average molecular weight, to the hundredths decimal place. Monoisotopic mass can be determined much more accurately than average molecular weight (1,2), thus the former is the preferred approach. Nevertheless, even with relatively large windows of 70 ppm, known unknowns can be routinely identified searching the CAS Registry by average molecular weight. Thereafter, the candidate list from the average molecular weight query can be further refined using monoisotopic mass and isotopic abundances as well as the number of associated references and key words.
Narrowing the Search of Databases to an Exact Structure
All candidate lists obtained by searching spectral or spectra-less databases are further refined, if possible, to a unique structure. Refinements of the lists are performed using a wide variety of additional ancillary information (1,2). This information includes EI spectra, CID spectra, sample history, the number of exchangeable protons (1,2,4), UV–vis diode-array spectra, nuclear magnetic resonance (NMR) data, types of ion adducts, relative retention times, the presence of related compounds in sample mixture, chemical derivatization, hydrolysis (9), and more.
Of this information, the most critical factor is the EI or CID spectrum of the known unknown. We often obtain both EI and CID spectra for an unknown because we find the GC–MS and LC–MS data yield complementary information. In many cases, the sample might require derivatization to form the trimethylsilyl derivative (10) for GC–MS analyses. The spectra are interpreted manually using model compound spectra obtained via the NIST similarity structure search of available reference databases. The NIST MS Interpreter utility correlates observed ions with molecular substructures for the model compounds as well as for the unknown and its associated putative structure.
Of course, not all components of a mixture are identified using our approach. Finding "No Results" (Figure 1) can occur for many reasons. Some compounds have relatively few associated references, or the appropriate keyword to properly prioritize the candidate list cannot be determined. Also, some compounds can convert in the sample matrix to "unknown unknowns." These "transformation products" (11) are not found in any spectral or spectra-less databases. In either case, we often succeed in identifying these additional compounds by correlating similar fragment ions and neutral losses of the unknowns to other components identified in the mixture.
Purchasing a standard of the material for comparison is, ultimately, the best means of confirming the identity of a known unknown. Both ChemSpider and SciFinder are particularly useful for finding commercial sources of standards. Also, identifications are routinely confirmed by using microreactions and known chemistry to prepare a mixture enriched in the compound of interest.
Examples That Illustrate the Process
The following section presents three typical examples of our approach for identifying known unknowns using spectra-less databases. No examples were included for the library search of EI and CID spectra because that approach is relatively straightforward. You can find many additional examples in our previous work, which includes detailed screen captures for SciFinder and ChemSpider queries (1,2).
Example 1: An additive was noted in a commercial polymer. The additive's molecular formula, as determined by accurate mass, LC–MS and ESI data, was C29H35N3O. Results from a SciFinder search of the CAS Registry by molecular formula were sorted by the number of associated references and the top hit was CAS No. 73936911, a UV absorber. The identification was confirmed by the major fragment ions noted in its accurate mass CID spectrum in positive ion mode (see Figure 3).
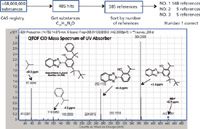
Figure 3: Confirmation of a polymer additive identification by the major fragment ions noted in its accurate mass CID spectrum obtained in positive ion mode.
Several other pieces of data supported this identification. The compound was shown by infusion ESI analysis to have one exchangeable proton. We routinely confirm exchangeable protons by both ND3 CI and ESI analyses (1,2,4). Furthermore, the UV–vis diode-array spectrum revealed the expected absorbances, 302 and 342 nm, for a UV absorber. The identity in this case was confirmed with data from a purchased reference standard.
Example 2: An unknown was noted in the extract of a can coating. Polymers used in food contact applications must meet strict criteria for extractables when appropriate food-simulating solvents are used. A polyester coating was applied to metal cans at a contract laboratory and the expected linear and cyclic polyester oligomers were observed in the extracts. In addition, an unexpected UV-absorbing species was noted with a molecular formula of C36H40O6. The references associated with the candidate list from SciFinder were further refined. "Can coating" was specified as a keyword, and the two likely isomeric structures shown in Figure 4 were found.
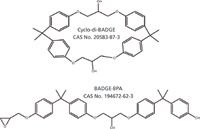
Figure 4: Structures of cyclo-di-BADGE and BADGE.BPA.
The negative ion electrospray data were consistent with the cyclo-di-BADGE (di-bisphenol A diglycidyl ether) isomer. BADGE. BPA yields both [M–H]- and [M + acetate]- anions, whereas cyclodiBADGE yields only the [M + acetate]- anion because the latter species contains no phenolic end group. The identification was confirmed by extracting a BADGE can coating and by preparation of BADGE. BPA from the reaction of BADGE with bisphenol A.
Cyclo-di-BADGE is a common, low-molecular-weight, cyclic monomer noted in the extracts from epoxy-based resins used in can coatings (12). The contract laboratory had inadvertently contaminated our coating with the material.
Example 3: An additive, whose monoisotopic mass was determined to be 783.520 ± 15 ppm, was observed in a polypropylene polymer. The top hit in the search of the ChemSpider database by monoisotopic mass yielded CAS No. 27676-62-6, an antioxidant, as the top candidate in the list when sorted by the "Number of References" field (see Figure 5).

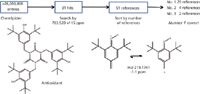
Figure 5: Identification of an antioxidant in polypropylene polymer.
The proposed identity was confirmed by accurate mass, CID fragmentation, which yielded the major ion at m/z 219 and three exchangeable protons by ESI infusion of the mixture. The supporting data were so convincing that the identification was immediately reported to the customer. At a later date, a standard of the material confirmed the initial identification.
Future Enhancements
Our current process for identifying known unknowns in simple mixtures is very useful and reasonably efficient. However, it is too time-consuming for complex mixtures. Although efficient, searches of EI and CID databases are significantly limited by the reporting process. We are working with several companies to resolve this limitation.
The searching and reporting of data from spectra-less databases is much more complicated and timeconsuming. The main bottleneck in the process is the manual interpretation of CID spectra. We have done some initial work using a "systematic bond-breaking" (13) approach that automatically scores the observed fragment ions in a CID spectrum to computer-generated fragment ions for candidate structures. Thus, a group of candidate structures are automatically exported from ChemSpider to Agilent's prototype version of the Molecular Structure Correlator program (14). The program sorts the results by the number of references, assigns a score based on observed ions versus computer-generated ions and displays substructures associated with accurate mass fragment ions. It would be useful if SciFinder would utilize a similar application program interface.
Finally, many chemical structures prove difficult to predict manually. For others, it is difficult to generate fragment ions using a computer. Therefore, it would be useful if the actual fragmentation (fragments and neutral loses) from model compounds in reference CID databases could somehow be correlated with the candidate structure.
Conclusions
Eastman Chemical Company has developed a systematic process for successfully identifying compounds in commercial products using a variety of approaches. The easiest approach uses a computer search of EI and CID spectra using the NIST MS Search program. The software, provided free of charge with the NIST EI and CID reference databases, enables us to create, archive and automatically distribute user databases to our worldwide corporate network.
The other approach uses web-based searches of spectra-less databases, such as ChemSpider and the CAS Registry, by molecular formula or molecular weight. The candidates are assigned priority according to the number of associated references or keywords. The top hits are then refined by their EI or CID spectra and many other orthogonal filters.
Supplementary Information
Supplementary information is available upon request from the author including library searching, library networking, additional examples of SciFinder and ChemSpider searches, selection of chemical ionization gases, silylation reactions and associated artifacts, polyester analyses, matrix ionization effects, and surfactant identifications.
Acknowledgments
Regrettably, it is not practical to individually recognize all those who have contributed to our approaches for identifying known unknowns in the last 34 years, though many are mentioned as authors in the references and associated acknowledgments. We will, however, acknowledge two individuals whose influence on this work is most eminent. The initial concepts originated from collaborations with Bill Tindall of Eastman Chemical Company. Steve Stein, of NIST, and his talented staff developed the software and utilities. CAS Registry Number is a registered trademark of the American Chemical Society.
References
J.L. Little, C.D. Cleven and S.D. Brown, J. Am. Soc. Mass Spectrom. 22, 348–359 (2011).
J.L. Little, A.J. Williams, A. Pshenichnov and V. Tkachenko, J. Am. Soc. Mass Spectrom. 23, 179–185 (2012).
S. Stein, Anal. Chem. 84, 7274–7282 (2012).
R.M. Parees, A.Z. Kamzelski and J.L. Little, The Encyclopedia of Mass Spectrometry Vol. 4, Fundamentals of an Applications to Organic (and Organometallic) Compounds, M.L. Gross and R.M. Caprioli, Eds., N.M.M. Nibbering, Vol. Ed. (Elsevier, Amsterdam, The Netherlands, 2005), pp. 772–780.
T. Kind and O. Fiehn, BMC Bioinformatics 7(234), doi:10.1186/1471-2105-7-234 (2006).
T. Kind and O. Fiehn, BMC Bioinformatics 8(105), doi:10.1186/1471-2105-8-105 (2007).
J.L. Little, Proceedings of the ASMS conference, Chicago, Illinois, (2001).
J.L. Little, Proceedings of the ASMS conference, Nashville, Tennessee (2004).
G.W. Tindall, R.L. Perry, J.L. Little and A.T. Spaugh, Anal. Chem. 63(13), 1251–56 (1991).
J.L. Little, J. Chromatogr. A 844(1–2), 1–22 (1999).
M. Zedda and C. Zwiener, Anal. Bioanal. Chem. 403, 2493–2502 (2012).
A. Schaefer and J. Simat, Food Addit. Contam. 21, 390–405 (2004).
A.W. Hill and R.J. Mortishire-Smith, Rapid Commun. Mass Spectrom. 19, 3111–3118 (2005).
J.L. Little, F. Kuhlman, L. Xiangdong, J. Zweigenbaum, A. Williams and V. Tkachenko, Proceedings of the ASMS conference, Vancouver, British Columbia, Canada (2012).
Curt Cleven is a technology associate at Eastman Chemical Company in Kingsport, Tennessee, USA.
Adam Howard is a technologist at Eastman Chemical Company in Kingsport, Tennessee, USA.
James Little is a research fellow at Eastman Chemical Company in Kingsport, Tennessee, USA. Direct correspondence can be sent to jameslittle@eastman.com.
"MS — The Practical Art" Editor Kate Yu joined Waters in Milford, Massachusetts, USA, in 1998. She has a wealth of experience in applying LC–MS technologies to various application fields such as metabolite identification, metabolomics, quantitative bioanalysis, natural products and environmental applications. Direct correspondence about this column should go to "MS: The Practical Art", LCGC Europe, 4A Bridgegate Pavilion, Chester Business Park, Wrexham Road, Chester, CH4 9QH, UK, or email the editor-in-chief, Alasdair Matheson, at amatheson@advanstar.com








; An Interview with Fabrice Gritti")
: An Interview With Fabrice Gritti")






A Novel LC–QTOF-MS DIA Method for Pesticide Quantification and Screening in Agricultural Waters
May 8th 2025Scientists from the University of Santiago de Compostela developed a liquid chromatography quadrupole time-of-flight mass spectrometry (LC–QTOF-MS) operated in data-independent acquisition (DIA) mode for pesticide quantification in agriculturally impacted waters.

Investigating 3D-Printable Stationary Phases in Liquid Chromatography
May 7th 20253D printing technology has potential in chromatography, but a major challenge is developing materials with both high porosity and robust mechanical properties. Recently, scientists compared the separation performances of eight different 3D printable stationary phases.

