|Articles|June 2, 2020
- Special Issues-06-02-2020
- Volume 6
- Issue 38
Challenges in Obtaining Relevant Information from One- and Two-Dimensional LC Experiments
Author(s)Bob W. J. Pirok, J.A. Westerhuis
To address the quest for greater separation power, the chromatographic community developed comprehensive two-dimensional liquid chromatography (LCxLC). But even with LCxLC, it can still be challenging to analyze highly complex samples and obtain accurate and correct information. In this article, opportunities for optimizing methods for extracting maximum information from one-dimensional (1D)-LC and two-dimensional (2D)-LC chromatographic data are explained.
Advertisement
Liquid chromatography (LC) methods are continuously improving to maintain our ability to meet the growing need of society to obtain more reliable information about a number of sample characteristics. With the samples subjected to LC analysis becoming increasingly complex, analysis of the resulting convoluted data has been increasingly challenging. To aid identification and quantification, LC systems were hyphenated with multichannel detectors (such as mass spectrometry [MS] and ultraviolet-visible spectroscopy [UV-vis]), which yielded relief to some extent, but also required new advanced data analysis methods. Not waiting for an answer, the chromatographic community resorted to the tool it understood best to address the quest for more separation power, and developed comprehensive two-dimensional (2D) chromatography. However, even with 2D chromatography, it can still be difficult to extract accurate and correct information from the results obtained for highly complex samples. Use of sophisticated detectors, such as high-resolution mass spectrometers, certainly helps, but also generates mountains of data. Arguably, extracting all relevant information is the biggest challenge currently faced in high-resolution chromatography. In this article, the challenge of and opportunities for extracting information from one-dimensional (1D)-LC and 2D-LC data is explained.
The increasing complexity of samples continues to demand more and more from liquid chromatography (LC) methods. To meet the call for better separations, scientists across the chromatographic community have enhanced the overall performance of LC in several ways. Well-known examples include the extremely efficient superficially-porous particles, novel stationary-phase monolithic materials, hardware to support ultrahigh-pressure liquid chromatography (UHPLC) conditions, and elevated temperatures. These approaches are generally aimed to improve the efficiency of the system, thus effectively reducing the peak widths and consequently the likelihood of peak overlap. However, Carr and associates demonstrated that these developments would mainly benefit from fast separations up to a limited number of analytes (1). Despite the use of state-of-the-art separation power, samples comprising of more than 50 analytes were shown to likely yield (partially) co-eluted peaks.
Fortunately for chromatographers, the chemometrics community proceeded to develop algorithms to extract as much accurate information (such as peak area for quantification) as possible from the increasingly more densely populated chromatograms. While we can find many of these algorithms in the data analysis software packages that accompany LC systems, the more convoluted signals become ever more challenging to unravel.
Background Removal
Generally, data analysis workflows start by removing the noise and baseline drift of the signal. In practice, a chromatographer will generally use blank measurements, but this is not always possible, or desired. More importantly, subsequent steps in the data-processing workflow, such as peak detection or multivariate methods, often rely on removing the background beyond that which can be achieved by simply subtracting a blank. Looking at just the last decade, this need for background removal has spurred the development of univariate and multivariate algorithms with more than 15 different methods (2).
The rationale for this astounding number of approaches can be found in three characteristics. First, “background” is an umbrella term for a large variation of different phenomena, ranging from simple baseline drift to the occurrence of complex systems peaks, and different phenomena require different solutions; second, successful background removal equals preventing accidental removal of sample-related information;, and third, the more sophisticated algorithms must be tailored to the characteristics of the dataset. In practice, the latter means that the user or algorithm must first determine optimal parameters for operation.
An example of a method to remove background is the local minimum value (LMV) approach (3). In Figure 1a, unprocessed data can be seen to contain the baseline drift resulting from the use of gradient elution. Figure 1b clarifies how the LMV approach literally searches all local minima of the signal (such as points that feature a lower signal than neighboring points; see Inset, Figure 2b). Using a moving-window approach and thresholding, outliers are identified along the chromatogram. Local minima on peaks or their edges (red points) can therefore be distinguished from the background (green points). Understandably, this and other strategies rely on the availability of data points that describe the background (3–5), thus becoming weaker when chromatograms are less sparsely populated and potentially preserving system peaks. Alternative approaches exist to tackle these limitations, but, despite their elegance (6), generally require more user input to work effectively in particular when more co-elution occurs. Unfortunately, numerical data comparing the vast number of strategies is limited (2).
Peak Detection and Analysis
Having removed the background, we can now shift our attention to the information of interest: the actual peaks. Traditionally, approaches for peak detection generally use either the derivatives of the signal, or curve-fitting strategies (7). Methods utilizing the derivatives exploit the fact that the peak apex as well as peak start and end points can be detected using the first- and second-order derivative of the signal, respectively. This strategy effectively amplifies the variation in the signal. To avoid local maxima (as present in noise) being recognized as peaks, derivative-based approaches generally rely on thorough removal of the background at the risk of removing sample information, potentially resulting in false negatives (for example. undetected components at trace concentrations) (8,9). Moreover, the use of derivatives becomes rather challenging when peaks are insufficiently resolved.
While this is also true for curve-fitting strategies, such matched-filter response approaches are arguably more forgiving. These least-squares methods attempt to fit a distribution function (such as a Gaussian) to the signal (10,11). To understand this, we remember that a Gaussian distribution can be expressed as
where s is the standard deviation of the distribution and m the mean. The curve-fit process essentially involves finding s and m values such that the residuals, the difference between the modeled Gaussian and the true signal (the error), are minimized. This approach typically utilizes optimization algorithms to iteratively update s and m, until the error is minimal. This is illustrated in Figure 2a, where the resulting Gaussian model (light blue) can be seen to match the data points. The residuals (purple lines) are plotted in Figure 2c, representing a total error of 1.72%.
Curve fitting is an elegant approach that, in contrast to derivative-based methods, does not necessarily require extensive preprocessing of the data (8). While we will see further how curve fitting can offer refuge in the event of co-eluted peaks, Figure 2b shows that this is limited when co-elution is too severe. Several peaks are undetected (light triangles) resulting in distorted fits of the actual detected peaks (dark triangles with individual light-blue curves). While the error is merely 0.813%, the wave patterns in the residual plot (Figure 2d) do note the deviation. Another piece of evidence can be found in the vastly different peak widths for the detected peaks (Figure 2b, light blue lines). It should be noted that both derivative-based and curve-fitting approaches struggle to detect peaks that are not prominently visible in Figure 2b. Indeed, the prominence of these peaks (the measure of how much a peak stands out due to its intrinsic height and location relative to neighboring peaks) is rather limited.
For peak detection by this approach to work in the event of severe co-elution, the strategy requires information on the number of peaks present, which ultimately is a peak detection problem. Ironically, to tackle this, curve-fitting approaches often exploit derivative-based methods to guide the least-squares process by offering the number of expected peaks and best guesses for the distribution functions. For example, if the curve-fit process is equipped with the suspected location of a peak, then this can be used as initial guess of the m parameter of the distribution function, thus increasing the likelihood of successful deconvolution is increased.
Deconvolution to Facilitate Quantification
Ultimately, the peak detection serves to subsequently obtain all relevant information from that peak. This, of course, includes the determination of the area to allow quantification. Figure 3a shows the detection and integration of peaks as commonly encountered in data-analysis software for LC instruments. Indeed, the way peaks 2 and 3 are divided (purple line) does not appear very accurate, because the actual shape of the peak is no longer preserved. Curve fitting appears to be an excellent method to tackle this problem. However, peaks in LC tend to tail slightly, even in the best separations. Consequently, it is of paramount importance that our distribution function can describe this asymmetric shape. In contrast to the symmetric Gaussian, the modified Pearson VII distribution represents the typical shape of a peak in LC rather well (12). It is expressed as:
where the additional parameter E represents the asymmetry of the peak, while M represents the shape, defined somewhere in between a modified Lorentzian (M = 1) and a Gaussian (M = ∞) shape. (13). Good estimate values for E and M are 0.15 and 5 (12).
The flexibility of equation 2 to adapt itself to the actual shape of the peak is expressed in Figure 3b, where the distribution function can be seen to accurately describe all four elution bands. In contrast, the Gaussian distribution cannot accommodate the asymmetric shape of LC peaks as accurately for this data (Figure 3c). These observations are supported by the residual plots in Figures 3d and 3e for the modified Pearson VII and Gaussian distribution, respectively. Indeed, in Figure 3d, the residuals appear to be randomly distributed as noise, whereas the pattern in Figure 3e reveals the misrepresentation of sections of the signal. Figure 3f shows that, after a limited number of iterations (<10), good fits can be obtained, representing a computation time of a few seconds.
More importantly, however, are the peak areas listed in Figure 3. The found area for peaks 2 and 3 using the local-maxima approach (Figure 3a) note 2.04 and 2.44, respectively. Using the modified Pearson VII as distribution function to accurately describe the peak shape, we obtain 2.37 and 2.36 using the curve-fitting approach (Figure 3b). This is a significant difference and indicates the importance of accurate deconvolution of peaks. However, a look at the numbers of 1.85 and 2.83 for peaks 2 and 3, respectively, as obtained using a Gaussian distribution function (Figure 3c), also underlines the magnitude to which curve-fitting approaches rely on the finding a representative distribution function. This threat adds to the questionable performance when even more peaks are co-eluted. Ultimately, non-random residuals are an important indicator for incorrect selection of peak shape and number of peaks.
At this point, it is relevant to note that, in contrast to the time domain, deconvolution is also possible in the frequency domain of the signal. While indispensable in data processing of spectroscopic data (7), it has also been extensively applied to chromatographic data (14), including two-dimensional data (15). Examples include the study of band broadening (16,17), but it is also applied for resolution enhancement (7). A recent example of the power of the latter is the work by Hellinghausen and associates (18). The work is a good example of how chemometric methods may yield additional “virtual” peak capacity without increasing the analysis time.
Returning to our time-domain deconvolution, one intrinsic problem with both the derivative-based and curve-fitting based methods is that they are designed to provide a binary answer to the questions of whether a signal is a peak or not. We have seen that this inevitably yields false negatives, and that information is lost. In this context, one interesting alternative peak-detection technique is therefore the probabilistic method by Lopatka and coworkers, which employs a Bayesian inferential approach (19). In essence, this approach exploits the statistical-overlap theory as prior information of existence of a peak. The algorithm postulates an array of exclusive hypotheses covering whether a peak is present or not, and evaluates these using least-squares. This strategy does not rely on the height of the peak, and should deserve additional attention.
Multichannel Data
Of course, chromatographers had a different solution to the problem of peaks co-elution. By hyphenating the LC with more sophisticated detection techniques such as diode-array detection (DAD), the powerful mass spectrometer yields more information to distinguish co-eluted peaks. Until now, we have addressed data analysis for data where only one property or variable is measured as a function of time, commonly referred to as first-order or single channel data. Using a DAD or MS detector, we measure an array of variables simultaneously, obtaining multichannel or second-order data. While data-analysis strategies in some cases approach these data from a single-channel perspective, such as the total ion-current chromatogram (TIC) or extracted-ion chromatogram (XIC), exploiting the multichannel content is often worth the investment. Multichannel data offer additional information to achieve more powerful deconvolution using multivariate methods. An example is multivariate curve resolution asymmetric least squares (MCR-ALS), which is applied to the dataset shown in Figure 4 to provide elution profiles and analyte spectra for all analytes detected.
In Figure 4a, we see the absorption for a range of wavelengths as a function of time plotted in a 3D surface, and can immediately understand that it is easier to spot differences between neighboring eluted species. For every point in time a UV-vis spectrum is obtained (Figure 4b). This is exploited by the MCR-ALS strategy, and the obtained individual elution profiles are plotted in the foreground for each compound. The approach not only allows resolving elution profiles of neighboring peaks, but also their corresponding UV-vis spectra. Similarly, multivariate data analysis methods for background correction have also been developed (20,21).
The information density in the detector dimension is arguably even higher for LC–MS data. When we trade the linear response of UV-vis for the resolution offered by MS, our dataset contains much more information and is considerably larger. This is particularly true when high-resolution MS instruments are employed. Even in cases of severe co-elution, it is often possible to find compounds present at trace concentrations using LC–MS.
Although multivariate methods are potentially more powerful to detect analytes in multichannel data, they are not yet commonly used by the chromatographic community. They are more difficult to automate (often needing prior information and parameter setting), and are, therefore, also less frequently supported in software packages accompanying the instrumentation. More experience and more interaction between developers and practitioners is needed for these methods to reach their full potential.
Comprehensive Two-dimensional LC
Chromatographers have responded with a familiar solution by adding a second separation dimension to their LC. Comprehensive two-dimensional liquid chromatography (LC×LC), where all fractions of first-dimension (1D) effluent are subjected to a second-dimension (2D) separation, certainly has delivered the much needed additional resolving power (22).
Unfortunately, while the added separation power may aid in reducing the likelihood of co-elution, it does not aid in extracting the key characteristics of the peaks. In contrast, particularly when multichannel detectors are used, higher-order data require innovative approaches.
That analysis of LC×LC data is more challenging is illustrated in Figure 5. The chromatogram in Figure 5a comprises a separation of an industrial surfactant sample (23). A background correction for such separations is not straightforward. For example, the characteristic elution of unretained species, resulting in a large signal, now results in a ridge across the entire chromatogram (Figure 5b). This ridge may shroud unretained analytes and is likely to change as the 1D gradient alters the 1D column effluent. Such phenomena require significantly different preprocessing strategies than the background encountered in the vicinity of resolved analytes (Figure 5c). At the same time, effects such as 1D column bleed, injection effects, as well as incompatible species introduced into the 2D separation may cause system phenomena which must be removed (Figure 5d).
Generally, LC×LC methods employ gradient elution in the second dimension to facilitate rapid elution and reduce the modulation time. The background signal induced by the gradient (Figure 5e) now must be removed from the entire 2D chromatogram. However, shifting gradients, which allows the 2D gradient to be changed for each individual modulation as a function of time (24), the background will be expressed differently for each modulation. Finally, the 1D is often sampled minimally to facilitate shorter analysis times (24). As a rule of thumb, 1D peaks are sampled three to four times by the 2D, significantly reducing the data available to describe the 1D peak shape. When this undersampling results in the loss of the ability to distinguish neighboring peaks, peak detection, integration, and thus quantification becomes challenging (Figure 5f).
To understand the cause, we must revisit the origin of the data. In LC×LC, the detector continuously measures the 2D effluent, resulting in a very long one-dimensional chromatogram (Figure 6a) which comprises a series of 2D chromatograms. Using the modulation time, the 1D chromatogram can be divided to obtain the individual 2D separations, which can be stacked next to each other. This process, typically referred to as folding the chromatogram, is highlighted in Figure 5b, with the dashed lines representing the individual 2D separations or modulations.
The chromatogram shown in Figure 6b is arguably difficult to interpret with the pixeled 1D information. With the 1D sampling rate depending entirely on the modulation time, Figure 6d strikingly underlines the shortage of data in the 1D. This is in stark contrast to the surplus of data in the 2D (Figure 6e). To achieve a smoother 1D profile and facilitate further data processing, the signal is often interpolated (25) resulting in the chromatogram as shown in Figure 6c.
The two most popular approaches for peak detection in 2D separations are the two-step and the watershed approach. The two-step approach first performs peak detection on the 1D data for each 2D chromatogram according to the derivative-based approach as discussed previously (26). Relevant peak characteristics are obtained through computation of the statistical moments. Next, a clustering algorithm is used to merge the signals in neighboring modulations which belong to the same chromatographic 2D peak (see Inset, Figure 6b). In contrast, the inverted watershed approach exploits the topology of the 2D surface to define the boundaries of the 2D peak (27).
Where the two-step algorithm is vulnerable to erroneous clustering in the event of severe co-elution, the watershed algorithm has been shown to be vulnerable to preprocessing and incorrect peak alignment (28). Both algorithms have since seen significant development, with improved peak alignment for the watershed algorithm (29) and a Bayesian two-step approach to benefit from multichannel detectors in four-way data (30). The magnitude of the peak-detection challenge is shown in Figure 6f. This 3D view of the inset of Figure 6c shows how interpolation may suggest the presence of two peaks, whereas the normal data (Inset, Figure 6b) also leave room for the signal to represent just one peak. With modern LC×LC methods employing shifting gradients and extremely fast 2D gradients (22), small shifts in retention across multiple modulations are not uncommon and can be different for each 2D peak within an LC×LC separation. This is also visible in Figure 6b, and suggests that method-wide retention time alignment may be insufficient to resolve this issue.
In these complex cases, the addition of multichannel detectors (such as LC×LC–MS and LC×LC-DAD) is the key to discern the true elution profiles of peaks. Two examples of multivariate techniques that are employed to tackle these complex higher-order datasets are MCR-ALS and parallel-factor analysis 2 (PARAFAC2) (31,32). Both techniques have been applied to LC×LC utilizing DAD and MS data and have shown to be highly useful (33–37). However, as with their application to 1D-LC data, these methods are currently still vulnerable for insufficient background correction and not straightforward to use. Often their application requires tailoring the algorithm with optimal parameters and constraints to the dataset. In this context, the development of PARAFAC2-based deconvolution and identification system (PARADISe) framework for gas chromatography–mass spectrometry (38) and LC–MS (32) is particularly interesting. This freely available platform was specifically designed to offer the power of PARAFAC2 to analyze chromatographic data with minimal user-defined settings. Similarly, toolboxes have been developed for MCR-ALS (39).
Multidimensional data-analysis techniques allow complex higher-order data generated by state-of-the-art (LC×)LC–MS and (LC×)LC-DAD methods to be unraveled. Their development may deliver increased information without increasing the analysis time. These techniques certainly deserve the attention from the chromatographic community, yet currently there appears to be a gap between development of such methods and large-scale use.
Acknowledgments
B.W.J. Pirok acknowledges the Agilent University Relations grant #4354 for support and Denice van Herwerden for her assistance with Figure 4.
References
- P. W. Carr, X. Wang, and D. R. Stoll, Anal. Chem.81(13), 5342–5353 (2009).
- T. S. Bos et al., J. Sep. Sci. submitted (2020).
- H.Y. Fu et al., J. Chromatogr. A1449, 89–99 (2016).
- X. Ning, I.W. Selesnick, and L. Duval, Chemom. Intell. Lab. Syst.139, 156–167 (2014).
- P.H.C. Eilers and H.F.M. Boelens, Life Sci. (2005). doi:10.1021/ac034173t
- M. Lopatka, A. Barcaru, M. . Sjerps, and G. Vivó-Truyols, J. Chromatogr. A1431, 122–130 (2016).
- A. Felinger, Data Analysis and Signal Processing in Chromatography (Elsevier Science Publishers B.V., Amsterdam, The Netherlands, 1998).
- K.M. Pierce and R.E. Mohler, Sep. Purif. Rev.41(2), 143–168 (2012).
- R. Danielsson, D. Bylund, and K.E. Markides, Anal. Chim. Acta454(2), 167–184 (2002).
- B. van den Bogaert, H.F.M. Boelens, and H.C. Smit, Anal. Chim. Acta274(1), 87–97 (1993).
- J. Beens, H. Boelens, R. Tijssen, and J. Blomberg, J. High Resolut. Chromatogr. 21(1), 47–54 (1998).
- B.W.J. Pirok et al., Anal. Chim. Acta1054, 184–192 (2019).
- G.R. McGowan and M.A. Langhorst, J. Colloid Interface Sci. 89(1), 94–106 (1982).
- A. Felinger, Anal. Chem.66(19), 3066–3072 (1994).
- A.T. Hanke et al., J. Chromatogr. A1394, 54–61 (2015).
- Y. Vanderheyden, K. Broeckhoven, and G. Desmet, J. Chromatogr. A 1465, 126–142 (2016).
- N.A. Wright, D.C. Villalanti, and M.F. Burke, Anal. Chem.54(11), 1735–1738 (1982).
- G. Hellinghausen, M.F. Wahab, and D.W. Armstrong, Anal. Bioanal. Chem.412(8), 1925–1932 (2020).
- M. Lopatka, G. Vivó-Truyols, and M.J. Sjerps, Anal. Chim. Acta817, 9–16 (2014).
- H.F.M. Boelens, R.J. Dijkstra, P.H.C. Eilers, F. Fitzpatrick, and J.A. Westerhuis, J. Chromatogr. A1057(1–2), 21–30 (2004).
- J. Peng et al., Anal. Chim. Acta683(1), 63–68 (2010).
- B.W.J. Pirok, D.R. Stoll, and P.J. Schoenmakers, Anal. Chem. 91(1), 240–263 (2019).
- B.W.J. Pirok, T.H. Halmans, R. Edam, and A.A. van Heuzen, Shell Global Solutions, unpublished (2015).
- B.W.J. Pirok, A.F.G. Gargano, and P J. Schoenmakers, J. Sep. Sci.41(1), 68–98 (2018).
- R.C. Allen and S.C. Rutan, Anal. Chim. Acta705(1–2), 253–260 (2011).
- S. Peters, G. Vivó-Truyols, P.J. Marriott, and P.J. Schoenmakers, J. Chromatogr. A 1156(1–2), 14–24 (2007).
- S.E. Reichenbach, M. Ni, V. Kottapalli, and A. Visvanathan, Chemom. Intell. Lab. Syst. 71(2), 107–120 (2004).
- G. Vivó-Truyols and H.-G. Janssen, J. Chromatogr. A1217(8), 1375–1385 (2010).
- I. Latha, S.E. Reichenbach, and Q. Tao, J. Chromatogr. A1218(38), 6792–6798 (2011).
- G. Vivó-Truyols, Anal. Chem. 84(6), 2622–2630 (2012).
- R. Bro, Chemom. Intell. Lab. Syst. 38(2), 149–171 (1997).
- B. Khakimov, J.M. Amigo, S. Bak, and S. B. Engelsen, J. Chromatogr. A 1266, 84–94 (2012).
- S.E.G. Porter, D.R. Stoll, S.C. Rutan, P.W. Carr, and J.D. Cohen, Anal. Chem.78(15), 5559–5569 (2006).
- M. Navarro-Reig, J. Jaumot, T.A. van Beek, G. Vivó-Truyols, and R. Tauler, Talanta 160, 624–635 (2016).
- M. Navarro-Reig et al., Anal. Chem. 89(14), 7675–7683 (2017).
- D.W. Cook, S.C. Rutan, D.R. Stoll, and P.W. Carr, Anal. Chim. Acta859, 87–95 (2015).
- R.C. Allen and S.C. Rutan, Anal. Chim. Acta 723, 7–17 (2012).
- A.B. Risum and R. Bro, Talanta 204, 255–260 (2019).
- R. Tauler, A. de Juan, and J. Jaumot, MCR-ALS Toolbox at <
http://www.mcrals.info/ >
B.W.J. Pirok is an assistant professor with the Analytical Chemistry Group, van ’t Hoff Institute for Molecular Sciences, Faculty of Science, at the University of Amsterdam, in The Netherlands. J.A. Westerhuis is with the Faculty of Science at the Swammerdam Institute for Life Sciences, at the University of Amsterdam, in the Netherlands. Direct correspondece to:
Articles in this issue
over 5 years ago
LCGC Special Issue PDFover 5 years ago
The Potential for Portable Capillary Liquid ChromatographyNewsletter
Join the global community of analytical scientists who trust LCGC for insights on the latest techniques, trends, and expert solutions in chromatography.
Advertisement
Related Content
Advertisement


Advertisement
Advertisement
Trending on LCGC International
1
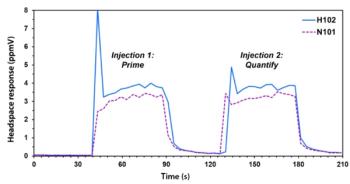
High-throughput Headspace Analysis of Volatile Nitrosamines and their Secondary Amine Precursors
2
Streamlined Method Development for Efficient and Reliable Lipid Nanoparticle Analysis
3
Best of the Week: The Scientific Method in the Age of AI, Rewiring the Fundamentals
4
Unlocking Discovery Data: Why a Digital Ecosystem Matters for HT-MS
5
