Plant Metabolomic Workflows Using Reversed-Phase LC and HILIC with ESI-TOF-MS
Special Issues
In plant metabolomics, molecular fingerprints and additional molecular descriptors can be identified using recent developments in polarity-extended separations with serial coupling of reversed-phase LC and HILIC combined with ESI-TOF-MS.
In the field of metabolomics, researchers seek to acquire almost complete information about the metabolic composition of a sample to provide fundamental information about the cellular state of organisms. In metabolomics analysis today, typically reversed-phase (RP) liquid chromatography (LC) is coupled with specific, sensitive, and robust mass spectrometry (MS). That approach, however, misses many moderately polar, and all very polar, compounds; this situation is a problem in plant metabolomics, because plant metabolites are mainly water-soluble species and thus very polar. Here, we describe new developments in polarity-extended separations using the serial coupling of reversed-phase LC and hydrophilic-interaction chromatography (HILIC) separation steps, in combination with electrospray ionization-time-of-flight-mass spectrometry (ESI-TOF-MS), and the application of this approach to plant metabolomics. The resulting retention time versus mass plots are molecular fingerprints, as well as sources of further molecular descriptors. Extraction methods, molecular analysis, and data evaluation have to be adapted to the matrix under consideration. Representative strategies using this polarity extending approach, following so-called suspects and nontargeted screening approaches, are presented.
Plant metabolomics, which is a comparatively young field, aims to provide almost complete molecular coverage of plant metabolites, to establish fundamental information about the plant under investigation based on changes in its metabolism (1,2). Plant metabolites can be roughly divided into primary and secondary metabolites. Secondary metabolites, although not used during plant growth and development, are important, because of their usage in plant defense, food, and medicine. Moreover, secondary metabolites play a substantial role in the adaptation of plants to environmental stress (3). Plants respond to exogenous factors through signaling pathways that induce downstream stress responses, including the modulation of gene expression and the regulation of a wide range of biochemical processes, ending with a remodeling of the metabolism (4).
Lemna minor (duckweed) is sometimes used as a model plant in plant metabolomics studies. It has also been proposed for phytoremediation of heavy metals in a glass house experiment (5). Additionally, L. minor has medical importance (6). Compared to other plant species, duckweed has a simple structure and rapid growth. Furthermore, L. minor is easy to harvest.
Targeted, suspects, and nontargeted screening strategies can be used for plant metabolite analysis (7). Targeted screening, formerly known as quantitative analysis, observes analytes using a reference substance. Compound identification and quantification has to be validated with isotopically labeled reference substances using mass spectrometry (MS) detection. Suspects screening typically is performed with accurate-mass and high-resolution mass spectrometry (HRMS) to observe the empirical formula of each formula present, or with tandem MS to observe specific fragment spectra. Subsequently, the empirical formula can be compared with chemical databases, such as Chemspider (http://www.chemspider.com), Chemicalize (https://chemicalize.com), or STOFF-IDENT (SI; https://www.lfu.bayern.de/stoffident), and with mass-spectrometric databases containing analytically observed mass spectra (such as MassBank, https://massbank.eu/MassBank/), or local databases in laboratories. If these databases lead to clear hits, one then has to validate the observation by an equivalent reference substance. Provided that the identity is proven, one can use it further in targeted screening analysis applying isotopically labeled standards. As stated before, this approach may require HRMS to generate the empirical formula of expected substances.
HRMS instrumentation is strictly needed when nontargeted screening is used as an analytical strategy. This screening strategy is split into screening for so-called hidden targets (also referred to as known unknowns) and unknown targets (also referred to as unknown unknowns). The hidden-target screening approach is similar to suspect screening, but starts without a list of metabolites or analytical databases. However, nontargeted screening data frequently can be compared with data in chemical and analytical databases (especially in retrospective analyses). For this purpose, analytical platform solutions are needed to handle nontargeted screening data. FOR-IDENT (FI; https://water.for-ident.org) is an open-access example of such a platform; it enables data evaluation by retention time index, accurate mass, and other important features of the molecule analyzed. The core of FOR-IDENT is a compound database called STOFF-IDENT, which is filled with anthropogenic compounds relevant in the aqueous environment. Another compound database under development is PLANT-IDENT, which contains general plant metabolites and includes exact masses, as well as other analytical results, and makes use of a retention index tool; this database is expected to encourage nontargeted screening in plant metabolomics.
Detailed metabolomics strategies (also for so-called unknown unknowns) are described in a 2014 paper (8). The nontargeted screening approach is encouraged by recent advances in HRMS that provide increased mass resolution and accuracy, enabling the identification of metabolites often simply by their accurate mass determinations, and by developments in tandem MS that enable the determination of accurate fragment spectra (containing additional structural information) (9). Gas chromatography–mass spectrometry (GC–MS) and reversed-phase liquid chromatography–mass spectrometry (LC–MS) are the methods of choice for qualitative and quantitative metabolomics analysis. The ultimate aim of nontargeted screening is to be able to accurately detect, monitor, and (eventually) identify every relevant metabolite in plant extracts, which cannot be achieved by any single existing analytical method. The methodology has to be thoughtful, from initial solvent extraction through chromatography via ionization and MS to data evaluation. Recently, plant metabolites analysis has been carried out through direct examination of crude extracts or after reversed-phase LC separation coupled with quadrupole MS, time-of-flight MS (TOF-MS), or other MS techniques, like ultrahigh-resolution Fourier transform ion cyclotron MS (FT–MS) (1).
The monitoring and identification of (very) polar compounds is important, because these compounds play a vital role in plant metabolic pathway changes. The use of hydrophilic interaction liquid chromatography (HILIC) columns in plant metabolomics analysis has facilitated the retention of polar and very polar compounds in a chromatographic column prior to elution into the mass spectrometer (10). The demand for a new analytical method that can identify a plant's metabolites in a single run has been answered previously (for red wine analysis [11]). The polarity-extended serial coupling of reversed-phase LC and HILIC, in combination with HRMS (12), allows for the robust and repeatable analysis of a large variety of compounds in a single run (13,14), and has been applied in several disciplines (11,15–18). In such polarity-extended studies, a new extraction method for sample preparation was confirmed that it is applicable to polarity-extended chromatography analysis (19). The current study focuses on the use of serial coupling of reversed-phase LC and HILIC, coupled to high-resolution TOF-MS and general data evaluation strategies for plant metabolomics, applied to the analysis of L. minor extracts. Therefore, samples were used before and after plant incubation with an exemplary (model) pharmaceutical that can influence the metabolism of the treated plants. Accordingly, new insights are provided, using accurate-mass MS and HRMS as well as novel data evaluation workflows.
Experimental
Reagents and Chemicals
Methanol and water were obtained in LC–MS grade from VWR (Darmstadt, Germany). L. minor was kindly provided by the German Research Center for Environmental Health, Plant Microbe Interactions, Helmholtz Centrum of Munich. Amino acids standards were obtained from Sigma (Missouri, United States).
Sample Preparation
First, 500 mg of freeze-dried and milled L. minor (incubated with and without 10 µM of diclofenac, respectively) were extracted with 5 mL of methanol. Extraction solvent was sonicated at 35 KHz (Sonorex super RK 106, Bandelin, Germany) with plant material for 10 min at 4 °C. Afterwards, the samples were centrifuged at 1500 rpm for 20 min, and the supernatant was transferred to a test tube. The extraction method was triplicated under exactly the same experimental conditions. Finally, the extracts were evaporated to dryness (using SpeedVac Fischer Scientific, Sweden), and redissolved in (50:50) methanol:water. The standard solutions and the solvent extract were injected three times, respectively.
Reversed-Phase LC and HILIC combined with ESI-TOF-MS
The polarity-extended serial coupling or reversed-phase LC and HILIC was connected via a Jet Stream ESI interface to an Agilent 6230 TOF-MS instrument (both Agilent Technologies, Santa Clara, California, United States), as described recently (11). Column effluent was coupled via a T-piece to an isocratic pump (Agilent Technologies, Waldbronn, Germany), which provides a constant flow of reference solution for MS calibration prior entering the ion source of the MS. The separation system consisted of an autosampler, a column oven, two columns, two binary pumps, and an ultraviolet (UV) detector (all Agilent Technologies, Waldbronn, Germany). The initial binary pump was connected to a nonpolar 120 EC-C18 Poroshell column (Agilent Technologies, Waldbronn, Germany). The outlet of this column was connected to a ZIC-HILIC column (Merck, Darmstadt, Germany), and to a second binary pump via a T-piece (Upchurch Scientific, IDEX, Illinois, USA). Ions were detected in positive ionization mode, with a mass range of 50–2100 Da. The instrument resolution was greater than 10,000 at m/z 922. The parameters were as follows: 325 °C gas temperature, 10 L/min drying gas flow, 325 °C sheath gas temperature, 7.5 L/min sheath gas flow, 45-psi nebulizer operating pressure and 100 V fragmentor voltage.
Data Processing
The data were evaluated with Agilent MassHunter Profinder B.08.00, Mass Profiler, and Mass Profiler Professional (MPP) 13.1.1 software. Profinder parameters applied for the automation of compound retention times (tR), and extraction and molecular weights, were set to a peak filter of 300 counts peak height, ion species to "positive ions" with H+, Na+ and K+, "charge state" to 1, and the "expected retention time" to ±3.00 min. The extracted ion chromatograms (EICs) were smoothed with a Gaussian function, using 9 data points width and 5000 points Gaussian width. Then, the "features" from the blanks dataset were deleted from sample datasets. These parameters limit the result for 2000 compound groups. The data set was exported to MPP. In MPP, the compounds were aligned. Subsequently, the retention times and masses were corrected, and C, H, O, N, and S atoms were used to compute the empirical formula of the compounds. The compounds' intensity logarithmic fold changes between the two samples are calculated and subsequently are drawn as a scatter plot. The calculated logD at pH 7.4 was based on the retention time/logD (pH 7) calibration curve of twelve different standards (18,20). The logD (pH) values were predicated from ChemAxon software (https://disco.chemaxon.com/apps/demos/logd/) and then exported to Windows Excel 2016 for further data evaluation. For hidden-target screening, the amino acids standards were organized, and injected three times. The mean of each of the standard masses (S) and tR values (S) were calculated in daltons and in minutes, respectively. The variation between the extract and the standard mean isotopic masses (Δ ppm) was calculated according to following equation:


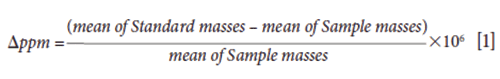
Moreover, the standard deviation (SD) of tR and relative standard deviation (RSD) were calculated.
Percent of RSD = SD of compound tR values in different injection divided by the mean of compound tR values.
The nontargeted measurements were evaluated through FOR-IDENT (FI; https://water.for-ident.org) and Metlin (https://metlin.scripps.edu/landing_page.php?pgcontent=batch_search) databases to search for expected and hidden targets ("known unknowns"). The workflow was conducted in the steps described below.
First, the list of accurate masses was uploaded into the database. The matching features were downloaded with their physiochemical properties. For FOR-IDENT results, the feature hits below a retention time of 15 min were filtered by excluding positive logD values. The amino acids were confirmed by reference standard injection (category 1) (21,22). However, cinnamic acid and other hits from the Metlin database remained as suspects (category 2) (21,22).
The log2-normalized data were used in statistical analysis to improve normality and group 2724 metabolites. Differences between the two samples were considered significant when the P value (calculated using a Student's t-test) cut-off was 0.05. The principal component analysis (PCA) was done using the multivariate analysis of OriginPro 2017. The heatmap was developed using MPP of the same data set as used in the PCA analysis.
Results and Discussion
Formerly, the serial coupling of reversed-phase LC and HILIC with ESI-TOF-MS was established for trace organic compound analysis in wine samples (10), water samples (15), and oxidative (17) as well as enzymatic conversion screening samples (18). More recently, this coupling is also being applied in plant metabolomic studies, such as to study metabolic changes caused by stress or by external compounds. L. minor is a good model plant for such studies and can easily be incubated, extracted, and analyzed.
The TOF-MS technique, and its specificity, allow accurate compound detection over a broad mass range (in different matrices). The so-called nontargeted screening strategy was performed in this study in positive ionization mode and with a mass range of 50–2100 Da. Concerning a typical methanol extract analysis of untreated L. minor samples with the serial coupling of reversed-phase LC and HILIC with ESI-TOF-MS, feature extraction was possible as shown in Figure 1. For such a feature, the retention time (tR), the accurate mass, and the signal intensity were extracted from a total ion chromatogram (TIC), each reflecting an independent (but still unknown) molecule. More than half of the isolated compounds (686) were retained and separated on the (very) polar HILIC column (blue colored triangular compounds in Figure 1; they are located with a retention time between 5 and 15 min, and have a logarithm of distribution coefficient logD [pH 7] < 0). In addition, 383 compounds were separated by reversed-phase LC (nonpolar) (red-colored circles compounds in Figure 1; they were eluted later than 16 min, and have logD values [pH 7] > 0), respectively. The empirical formula could be predicted for most features. The data sets were evaluated via nontargeted screening strategies as described above in the introduction and references therein.


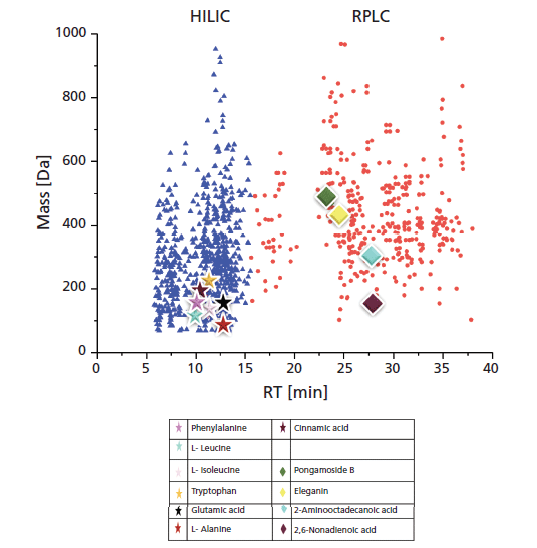
Figure 1: Retention time versus mass plot of Lemna minor extract (of an untreated sample). Blue triangles represent hydrophilic interaction liquid chromatography (HILIC)-retained molecules eluted from 0 to 15 min; red circles represent reversed-phase LC-retained molecules eluted from 16 to 38 min. Different colored and shaped dots represent examples of identified (stars) and expected (diamonds) compounds, as indicated in the legend.
First, the nontargeted screening data were evaluated by exporting results to the open-access platform FOR-IDENT. There, the features were uploaded and the normalized retention time (tR) and accurate mass were compared with the compound database STOFF-IDENT (containing anthropogenic compounds expected in the aqueous environment). This search yielded several hits of suggested compounds with respective empirical formula and logD values. Applying this strategy resulted in hits and suggested compounds containing amino acids and organic acids (see Figure 1; specifically, molecules labeled with stars and included in the table). For example, glutamic acid and cinnamic acid were the only hits in STOFF-IDENT for 147.0532 Da and 148.052 Da, respectively. Thus, one can confirm the identity of both very quickly and easily by measuring the respective reference substance for each compound.
However, the process is not always that simple. For example, the mass of 165.079 gives 10 matches, of which nine have a positive logD value, and one a negative value. Thus, the nine matches could be deleted, because the feature eluted in the negative logD region was retained by HILIC. The remaining hit (after deletion) was the amino acid phenylalanine and could easily be evaluated further by comparing to reference material.
Sometimes the use of compound databases does not lead to such unequivocal results. For example, a feature at 89.048 Da resulted in five hits. After excluding the two positive logD values, three hits were remaining with negative logD values. L-alanine was confirmed by a reference standard also eluting in the HILIC region. In general, this strategy leads to explicit and filtered suggestions for compound identities.
Furthermore, tryptophan, leucine, and isoleucine (as shown in Figure 1) were identified similarly. After excluding the positive logD results, the remaining hits with negative logD values were either the corresponding amino acid, or various synthetic compounds. Later hits are typically anthropogenic (brought into the environment), and cannot be originated in the plant, thus they were neglected in this study. Reference standards for the remaining amino acids were injected to prove the identity and presence in the L. minor extracts, which also were reported previously in the literature (24). Finally, for the successful application of the hidden-target screening strategy (7) using the compound database STOFF-IDENT, amino acid standards were available, directly confirming the hits of expected amino acids in L. minor methanol extracts. The amino acids identified are phenylalanine, L-leucine, L-isoleucine, tryptophan, glutamic acid, and L-alanine, as labeled in Figure 1. The amino acid standards were injected in triplicate, and the mean of each standard mass (S) and retention time were calculated. The identification was done through comparing the differences between the mean retention times of the standard and extract, which was in the range of 0 min (phenylalanine) to 0.15 min (tryptophan). Moreover, the mass variation between the standard mass (S) and the extract mass (M) is less than 5 ppm. In Table I, the six identified amino acids were listed with their mean isotopic mass and mean retention times. In addition, standards mean isotopic mass and retention times were calculated for the three injections.


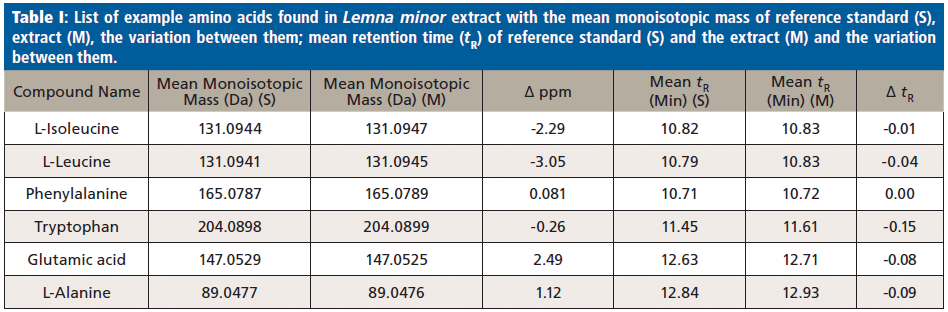
The identification was done using the following workflow. The differences in tR (ΔtR) between the standard and the extract were in the range of ≈0–0.15 min. The variations between the extract and the standard mean isotopic masses (Δ ppm) were calculated in the six amino acids. The Δ ppm values were in the range of –3.05 for L-leucine to +0.08 for phenylalanine. All the amino acids were in the same retention time and mass range as formerly reported for the serial coupling of HILIC and reversed-phase LC in an aqueous environment (15). Also, without using tandem MS (and its significant fragment spectra) the hits resulted in category 1 of the identification scheme published earlier (21,22).
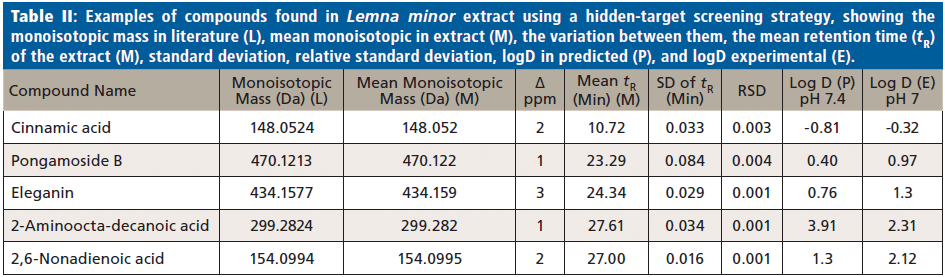
Generally, nontargeted screening data from plant extracts can be compared with an available metabolomics compound database like Metlin (https://metlin.scripps.edu/landing_page.php?pgcontent=batch_search) to find expected molecular hits using the hidden-target strategy described previously. A disadvantage compared to the FOR-IDENT platform is that other databases like Metlin have no automated comparison functionality. In applying the Metlin database, four compounds were identified by manually comparing the tR and logD of the compounds with the literature; these compounds were pongamoside B, eleganin, 2-aminooctadeconic acid, and 2,6-nonadienoic acid (Figure 1). These compounds and cinnamic acid (additionally observed in FOR-IDENT) were not yet confirmed by standards; thus, these compounds remain in category 2 as suggested by references (21,22). However, the four compounds presumably identified through Metlin and cinnamic acid by the same workflow are listed in Table II. The variation between measured monoisotopic mass and the mass found in the literature is less than ±4 ppm. Moreover, the standard deviation (SD) of tR and relative standard deviation (RSD) were calculated. The all-compounds RSD values were <0.1% for the three injections, which indicates the reproducibility of the LC method, and as formerly reported for the serial coupling of HILIC and reversed-phase LC (15). Consequently, the tR for each compound could be used in the standards tR indices calibration curve to calculate the logD (pH 7) (20,25). The lower polarity limit of polar compounds was set to a logD (pH 7) value of zero because of the reversed-phase LC column used; therefore, it can likely retain compounds above this polarity. The polarity region below logD zero in this study is restricted to HILIC (15). Pongamoside B, eleganin, 2-aminooctadeconic acid, and 2,6-nonadienoic acid were retained by reversed-phase LC, thus their tR values were longer than 15 min. The experimental logD values of suspect compounds were calculated from the 12 standards calibration curve of logD (pH7) and retention time index. The difference between experimental and predicated logD (pH 7) values was in the range of 0.5 (cinnamic acid) to 1.6 (2-aminooctadecanoic acid). Subsequently, the calculated logD values for all compounds are compatible with the literature logD values. In consideration of supporting parameters, such as variation between masses, tR, and logD values of cinnamic acid, pongamoside B, eleganin, 2-aminooctadeconic acid, and 2,6-nonadienoic acid were presumably identified through the Metlin database using the hidden-target screening strategy.


However, identifying molecules and "calling them by name" often is not the goal of nontargeted screening measurements or workflows. Moreover, nontargeted screening of the total sample may inform researchers about recent changes in the metabolome in combination with statistical tools and graphical visualization. For instance, direct feature comparison (19), PCA (26), heat plots (27), and clustering (28) were used to reduce and visualize the complex metabolomics datasets (23).
A study in the laboratory using the model plant L. minor was performed by incubation with 10 µM of the pharmaceutical diclofenac, which may be enriched in the plant, metabolized in the plant, or change the plant's metabolic pathways. The latter can be monitored in principle by nontargeted screening measurement and subsequent application of statistical tools like the above stated direct sample comparisons or PCA.
In sample comparisons, features were found reflecting L. minor samples with and without pharmaceutical incubation, which were located on the y-axis in Figure 2a, and on the x-axis in Figure 2e, respectively. Other compounds were not affected by incubation, and had the same signal intensity in the untreated as well as treated samples, thus located in the middle part of the comparison plot (see Figure 2c). However, some compound intensities were increased due to incubation, and are located in the upper part in Figure 2b. Others were decreased due to incubation, and are found in the lower part of Figure 2d.


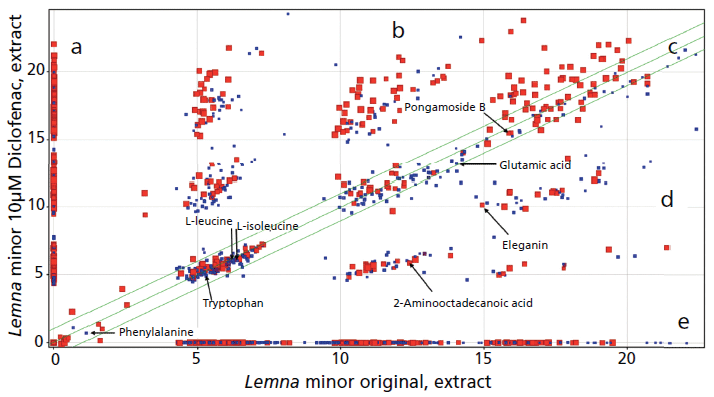
Figure 2: Feature (signal intensity) comparison plot of an extract using original untreated Lemna minor sample versus an extract of L. minor sample treated with 10 µM of diclofenac. Examples of found amino acids and expected compounds are found in both samples. Small blue squares represent retention time (tR) (0-15 min) and big red squares represent the tR (16-38 min) of (a) compounds only found in the Lemna sample treated with 10-µM diclofenac extract; (b) compounds found in both samples with increased feature intensity in treated compared to untreated Lemna samples; (c) compounds found in both samples; (d) compounds found in both samples with decreased feature intensity in treated compared to the untreated Lemna sample; and (e) compounds only found in the untreated Lemna sample extract.
The category 1 identified phenylalanine, tryptophan, L-leucine, glutamic acid, L-isoleucine, and category 2 identified pongamoside B were found in the two samples with the same intensity (see Figure 2c). Consequently, incubation with diclofenac or its degradation products might not affect their biosynthetic pathways. However, the incubation of L. minor with diclofenac caused decreases in the intensity of some compounds. Category 2 identified eleganin and 2-aminooctadececanoic acid have a higher intensity in the original samples, indicating that diclofenac or its degradation products affected their biosynthetic pathways. Accordingly, incubation of L. minor with 10-µM diclofenac causes changes in its metabolome by altering the intensity or disappearance of the compounds.
PCA of the samples showed that samples were grouped into two groups (Figure 3). L. minor with 10-µM diclofenac was related to principal component 1 (PC1), whereas the original untreated sample was related to principal component 2 (PC2). The dots (features) located in the upper left part (the positive part of principal component 2) represent the compounds related to the untreated sample (see Figure 3a). Also, the compounds related positively to both samples are located in the upper right part of Figure 3b. Furthermore, the compounds related negatively to both samples are located in lower left part of Figure 3c. However, the compounds related to treated samples are drawn in the positive region of PC2 (see Figure 3d).


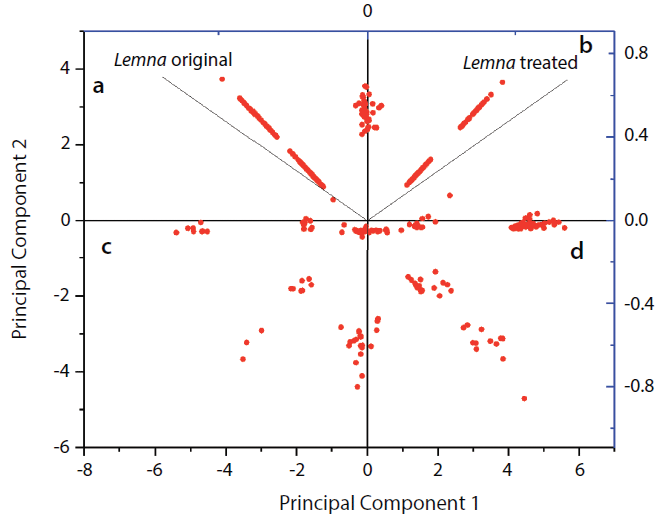
Figure 3: Principal component analysis (PCA) plot of features occurring in untreated Lemna minor sample extract versus L. minor sample extract treated with 10-µM diclofenac: (a)Dots represent the compounds related positively to untreated sample and negatively to treated sample; (b) dots represent compounds that are positively related to both samples; (c) dots represent compounds that are negatively related to both samples; (d)dots represent compounds related positively to treated sample and negatively to untreated sample.
In addition, the heat map of the L. minor with 10-µM of diclofenac and the original samples presented the compounds intensities in the two samples. The blue color indicates that the compounds have low intensity and the red color indicates that the compounds have higher intensity. As an example, glutamic acid was found with low intensity –5.81 and –6.62 in L. minor original untreated and treated with 10 µM of diclofenac, respectively (Figures 4a and 4b).


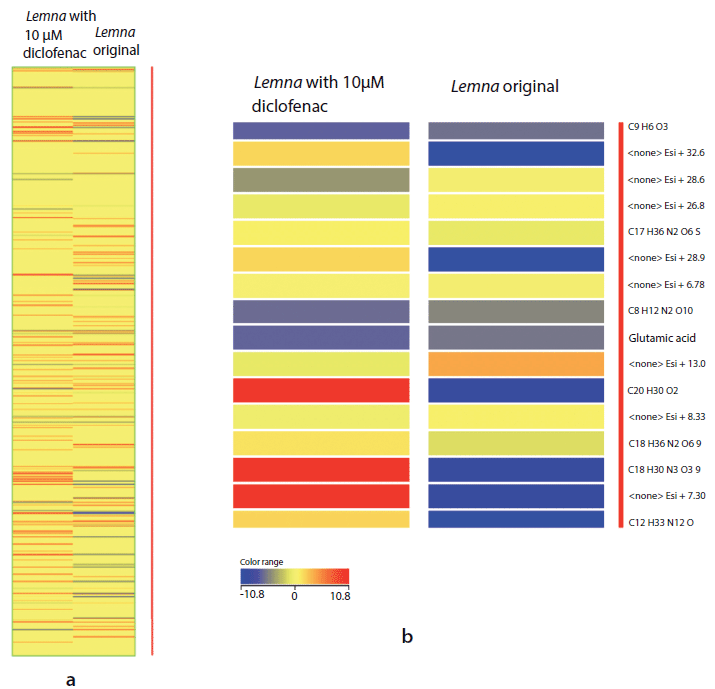
Figure 4: (a) Heatmap plot of different compound intensities in untreated Lemna minor sample extract versus Lemna minor sample extract treated with 10 µM of diclofenac (with glutamic acid as an concrete example). (b) Magnified view of a part of the heatmap. Red color indicates higher intensity of compound in the sample. The compound intensity is ≤10.8. However, the blue color indicates lower intensity, which means intensity is ≥ -10.8. The yellow color indicates the absence of compound in the sample, which means the intensity is equal to zero.
Conclusion
Advances in MS are driving nontargeted screening by generating an accurate empirical formula, using tandem MS with structural information observed by molecule fragmentation (not in this study), and normalizing retention times and correlating the latter with logD values. Thus, the application of data evaluation platforms and compound databases can be helpful in identifying compounds that lack reference standards, by searching for the exact masses in a hidden-target screening approach, and to analyze suspect metabolites in nontargeted screening. A new database resembling FOR-IDENT, that will focus on plant metabolites, will be launched. The new database, PLANT-IDENT, will have the same concept and advantages of the FOR-IDENT platform. Moreover, the new database will decrease the number of hits compared to chemical databases like Chemspider.com, and thus will avoid many false positive results. The launch of this database will help researchers who use highly sensitive mass spectrometers in identification of plant metabolomics through nontargeted screening.
In this study, extracts containing untreated or pharmaceutical-incubated L. minor plants were investigated with nontargeted screening strategies like hidden-target screening. The applied workflow in L. minor metabolite analysis will be a touchstone for subsequent research. Even when using different mass spectrometers, researchers can apply this workflow with or without reference materials to identify suspect and hidden targets. The statistical nontargeted screening workflow was conducted through different statistical tests to monitor metabolite differences between different samples. In addition, it allows the monitoring of metabolites changes. Studies that are more complex might require more complex or combined statistical tools.
Acknowledgments
This study was partially supported by the Bavarian State Ministry of the Environment and Consumer Protection. Dr. Andrés Sauvêtre is thanked for the cultivation, incubation and harvesting of the applied L. minor samples.
References
(1) R. Hall, M. Beale, O. Fiehn, N. Hardy, L. Sumner, and R. Bino, Plant Cell 14(7), 1437 LP-1440 (2002).
(2) F.T. Jorge, T.A. Mata, and A. Carla, Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 374(2079), 20150370 (2016).
3. J.N. Kabera, E. Semana, A.R. Mussa, and X. He, J. Pharm. Pharmacol. 2, 377–392 (2014). doi:10.1016/0300-9084(96)82199-7.
4. N. Shitan, Biosci. Biotechnol. Biochem. 80(7), 1283–1293 (2016).
5. S.H. Bokhari, I. Ahmad, M. Mahmood-Ul-Hassan, and A. Mohammad, Int. J. Phytoremediation 18(1), 25-32 (2016). doi:10.1080/15226514.2015.1058331.
6. X. Zhao, G.K. Moates, N. Wellner, S.R.A. Collins, M.J. Coleman, and K.W. Waldron, Carbohydr. Polym. 111, 410–418 (2014). 1016/j.carbpol.2014.04.079".
7. T. Letzel, A. Bayer, W. Schulz, A. Heermann, T. Lucke, G. Grecoa, S. Grosse, W. Schüssler, M. Sengl, and M. Letzel, Chemosphere 37, 198-206 (2015). doi:10.1016/j.chemosphere.2015.06.083.
8. T. Letzel, Lab More Int. 14–18 (2014). at http://www.int.laborundmore.com/archive/555305/Nontargeted-screening,-suspected-target-screening-and-target-screening-of-technologies-and-philosophies,-databases-and-crafts.html.
9. T. Letzel and J. E. Drewes, ACS Symp. Ser. pp. 175–181 (2016). doi:10.1021/bk-2016-1242.ch010.
10. T. Letzel and G. Greco, J. Chromatogr. Sci. 51(7), 684–693 (2013).
11. G. Greco, S. Grosse, and T. Letzel, J. Sep. Sci. 36(8), 1379–1388 (2013).
12. G. Greco and T. Letzel, LCGC North Amer. 10(2s), 40–44 (2012).
13. G. Greco, S. Grosse, and T. Letzel, J. Sep. Sci. 37(6), 630–634 (2014).
14. G. Greco, A. Boltner, and T. Letzel, Am. J. Mod. Chromatogr. 1(1), 12–25 (2014).
15. S. Bieber, G. Greco, S. Grosse, and T. Letzel, Anal. Chem. 89(15), 7907-7914 (2017). doi:10.1021/acs.analchem.7b00859.
16. S. Bieber and T. Letzel, LCGC Europe 31(11), 602–608 (2018).
17. M. Rajab, G. Greco, C. Heim, B. Helmreich, and T. Letzel, J. Sep. Sci. 36(18), 3011–3018 (2013).
18. L.F. Stadlmair, S. Grosse, T. Letzel, J.E. Drewes, and J. Grassmann, Anal. Bioanal. Chem. 411(2), 339-351 (2018). doi:10.1007/s00216-018-1442-7.
19. R. Wahman, J. Grassmann, P. Schröder, and T. Letzel, Unpublished work, (2019).
20. S. Grosse, and T. Letzel, User Man. Stoff-IDENT Database 4.1, 1–33 (2016).
21. E.L. Schymanski, J. Jeon, R. Gulde, K. Fenner, M. Ruff, H.P. Singer, and J. Hollender, Environ. Sci. Technol. 48(4), 2097–2098 (2014).
22. T. Letzel, T. Lucke, W. Schulz, M. Sengl, and M. Letzel, Lab More Int. 24–28 (2014).
23. J.E. Schollée, E.L. Schymanski, and J. Hollender, Transform. Prod. Chem. by Nontargeted Suspect Screen.-Strateg. Work. Vol. 1 1241, 4–45 (American Chemical Society, 2016).
24. W. Maciejewska-Potapczyk, L. Konopska, and K. Olechnowicz, Biochem. und Physiol. der Pflanz. 167(1), 105–108 (1975).
25. FOR-IDENT (2019). available at https://www.for-ident.org/
26. Y. Wang, L. Xu, H. Shen, J. Wang, W. Liu, X. Zhu, R. Wang, X. Sun, and L. Liu, Sci. Rep. 5, 18296 (2015).
27. Q. Zhang, Y. Shi, L. Ma, X. Yi, and J. Ruan, PLoS One 9(11), e112572 (2014).
28. P.H. Benton, J. Ivanisevic, D. Rinehart, A. Epstein, M.E. Kurczy, M.D. Boska, H.E. Gendelman, and G. Siuzdak, Metabolomics 11(4), 1029–1034 (2015).
Rofida Wahman, Johanna Grassmann and Thomas Letzel are with the Technical University of Munich in Munich, Germany. Peter Schröder is with the German Research Center for Environmental Health in Munich, Germany. Direct correspondence to T.Letzel@tum.de.





; An Interview with Fabrice Gritti")
: An Interview With Fabrice Gritti")




. From industry he went on to Florida State University, where he was assistant professor of both analytical and materials chemistry. Since 2011, he has been at the National Institute of Standards and Technology (NIST), where he is currently Scientific Advisor in the Chemical Sciences Division. André is the author of over 90 peer-reviewed scientific publications, lead author of the second edition of “Modern size-exclusion liquid chromatography,” editor of the book “Multiple detection in size-exclusion chromatography,” past associate editor of the Encyclopedia of Analytical Chemistry and, since 2015, editor of Chromatographia. He has received a number of awards, including the inaugural ACS-DAC Award for Young Investigators in Separation Science, and was also inaugural Professor in Residence for Preservation Research and Testing at the US Library of Congress. His interests lie principally in the area of macromolecular separations, both fundamental and applied.")

New Method Explored for the Detection of CECs in Crops Irrigated with Contaminated Water
April 30th 2025This new study presents a validated QuEChERS–LC-MS/MS method for detecting eight persistent, mobile, and toxic substances in escarole, tomatoes, and tomato leaves irrigated with contaminated water.

